【排序算法】计数排序引发的围观风波——一种O(n)的排序 agile Posted on Jul 13 2023 排序算法 ## 前言 计算机课上,老师给一串数字**6 1 6 9 9 1 4 2 1 5 8 8**,问道:这一串数字,你们写个程序给我看,要求效率较高。学不出来的别下课了。 顿时场下一片哗然,但有很多小朋友硬着头皮啪啪啪的开始敲了。 老师走到**pigpian**身边,**pigpian**很难得皱了皱眉头  很难很难得写下了下面代码: ```java int a[]= {6,1,6,9,9,1,4,2,1,5,8,8}; for(int i=a.length-1;i>=0;i--) { for(int j=0;j<i;j++) { if(a[j]>a[j+1]) { int team=a[j]; a[j]=a[j+1]; a[j+1]=team; } } } System.out.println(Arrays.toString(a)); ``` **老师**:"gun吧,都2020年还用O(n2)得算法,快,快回去吃饭吧,快gun吧"。**pigpian**一脸无奈得走出教室,接着老师问道有没有其他人写出来,慢慢得挪到**doudou**得旁边。 **doudou**着急解释道:老师,你看我的O(nlogn)得快排算法: ```java int a[]= {6,1,6,9,9,1,4,2,1,5,8,8}; Arrays.sort(a); System.out.println(Arrays.toString(a)); ``` 老师轻蔑得嘲讽道:"gun 吧,就知道投机取巧,我看你海!回去吃饭吧" 紧着着老师走到**bigmao** 的旁边,**bigmao** 给老师看了他的代码: ```java private static void quicksort(int [] a,int left,int right) { int low=left; int high=right; //下面两句的顺序一定不能混,否则会产生数组越界!!!very important!!! if(low>high) return; int k=a[low];//取最左侧的一个作为衡量,最后要求左侧都比它小,右侧都比它大。 while(low<high) { while(low<high&&a[high]>=k) { high--; } //这样就找到第一个比它小的了 a[low]=a[high]; while(low<high&&a[low]<=k) { low++; } a[high]=a[low]; } a[low]=k; quicksort(a, left, low-1); quicksort(a, low+1, right); } ``` 老师脸角泛起微光:"不错不错,**手写快排**还是挺棒的,回去吃饭吧!"。 此时**bigsai**举起他的小手手:"老师快来,我写的这个贼快"。bigsai亮起他的代码: ```java int a[]= {6,1,6,9,9,1,4,2,1,5,8,8}; int count[]=new int[10]; for(int i=0;i<a.length;i++) { count[a[i]]++; } int index=0; for(int i=0;i<count.length;i++) { while (count[i]-->0) { a[index++]=i; } } System.out.println(Arrays.toString(a)); ``` "不错不错,这个方法效率确实很高,你回去把这种排序的方法和大家分享一下吧!"老师惊艳道! 待**bigsai**出门后,站在门外的**pigpian**和**doudou**拦住问道:"sai哥这是啥东东啊"。 **"计数排序。流程看图,听我下面慢慢讲:"** 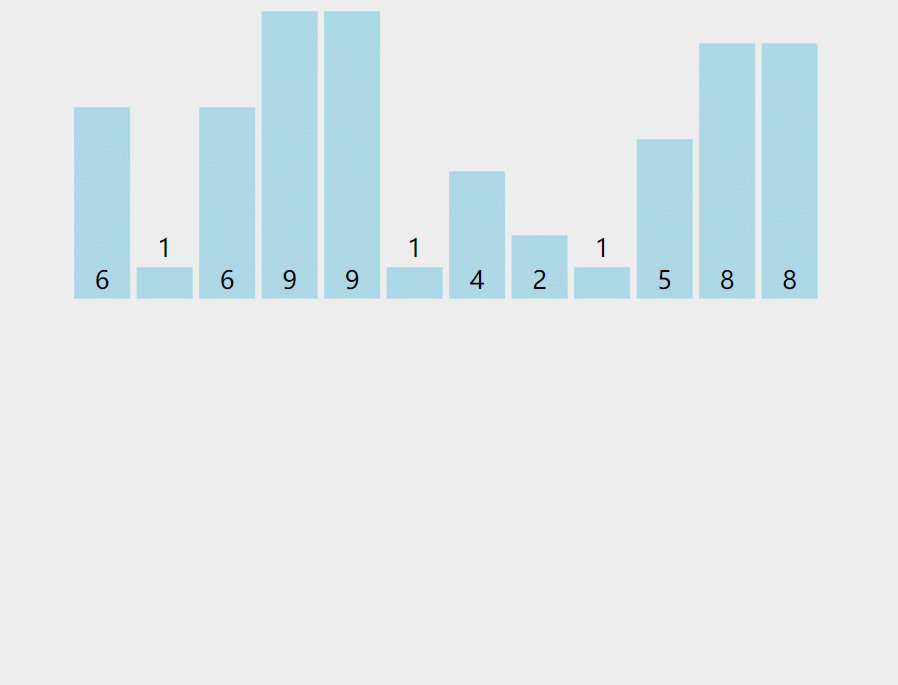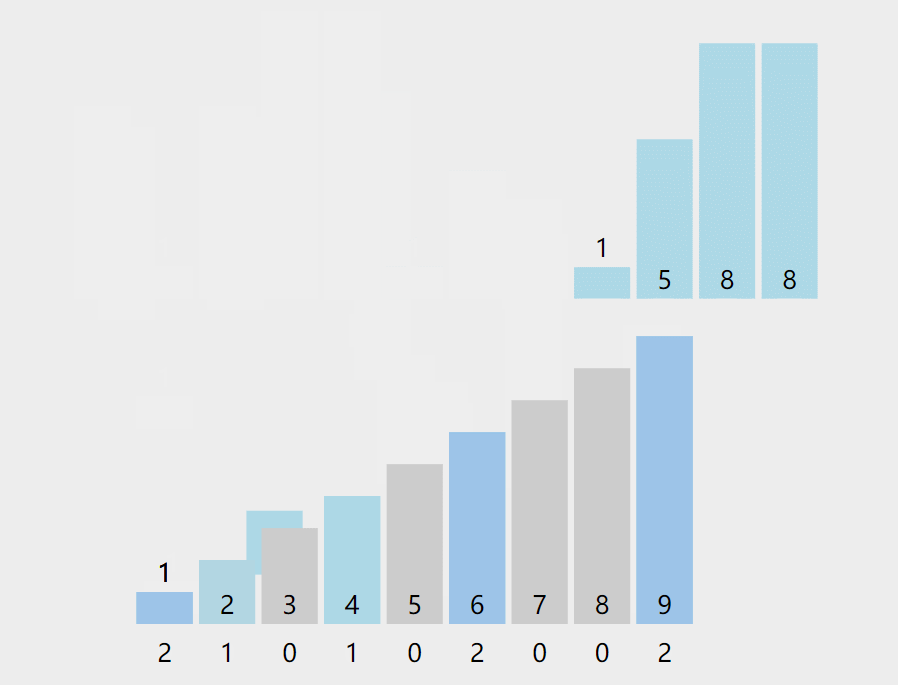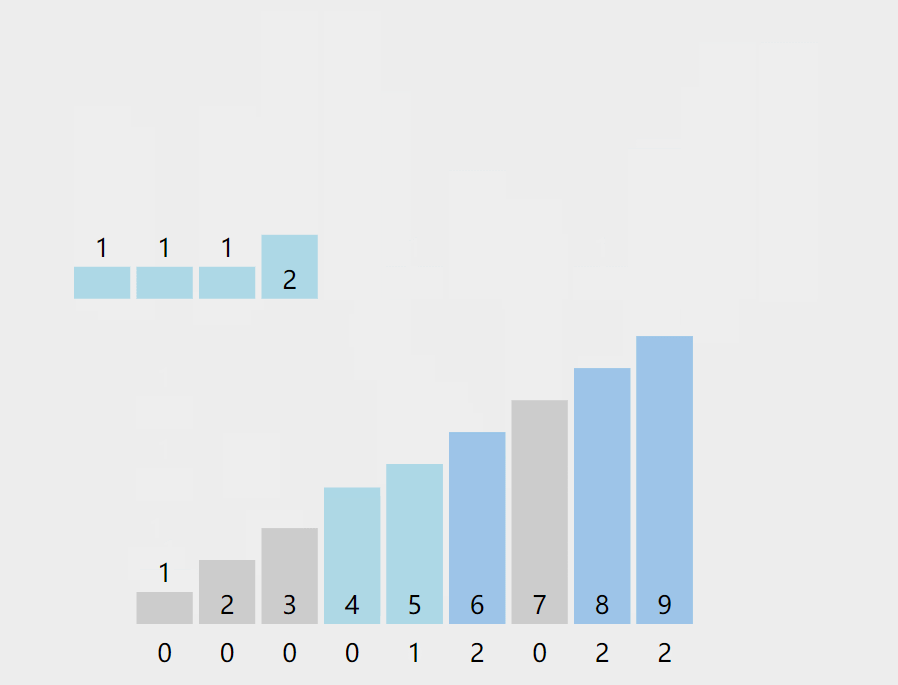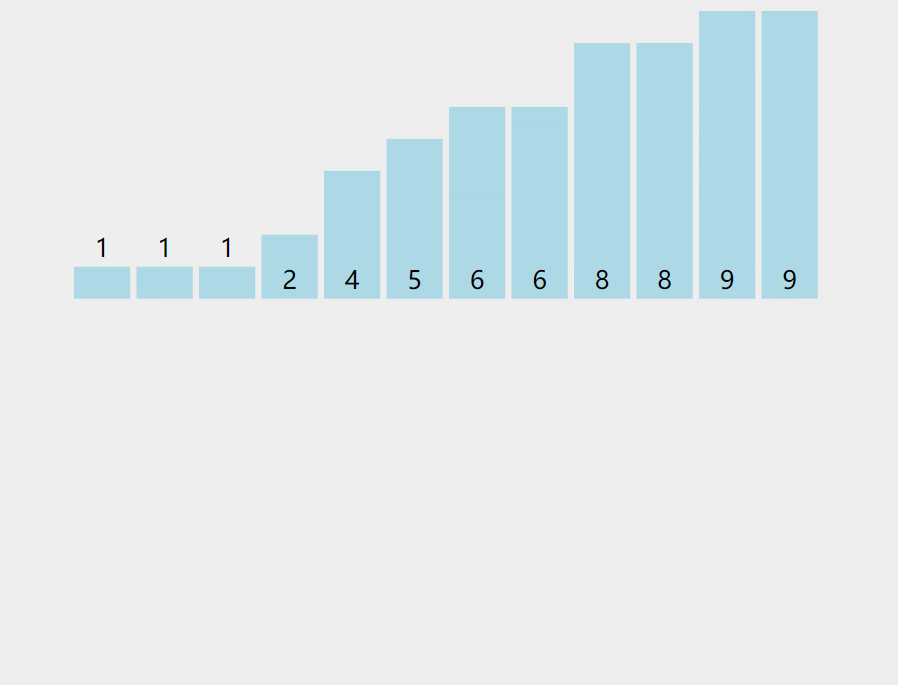 ## 计数排序介绍 或许上面的代码你看起来还有点懵逼,但是不要紧,我们在这里给你讲明白什么是计数排序。对于计数排序,百度百科是这么说的: >计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为`Ο(n+k)`(其中k是整数的范围),快于任何比较排序算法。 当然这是一种牺牲空间换取时间的做法,而且当`O(k)>O(n*log(n))`的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是`O(n*log(n))`, 如归并排序,堆排序) 对于额外数组该如何理解呢? 我们慢慢来,在**以前介绍桶排序的时候**,我们知道每个桶里面是可以给一个范围的数字放进去。从每个桶的实质来看可以是**List集合**。  但如果每个桶中只有**一种元素**,那么这个桶就可以不需要使用集合去储存标记,而是用一个数字即可进行标记**认为它出现了多少次**。  所以这种每个桶只能放一种元素的,我们不需要每个桶再用List集合去装,而用数组的值储存对应编号出现的词数即可,例如上述的`a[1]=2`表示其中的1号桶出现两次,而`a[3]=0`表示元素3没有出现过。 而这样的数值如何计算呢? - 很简单,对待排序目标序列遍历一次,每次遍历的值让这个值的编号加上1,说明对应元素词数加一。例如上述第一个1就a[1]++,第二个5就a[5]++…… - 然后取值时候遍历这个数字,顺序将目标编号的数字取出来即可。(每取一个对应位置数值减1直到为0为止)。例如上述遍历这个数组,就获得`1 1 2 4 4 5`这个序列。你看看,这个时间复杂度是不是O(n)的? 上面算法设计就很好了嘛?当然不是,如果是1,2 ,3之类数据肯定没啥问题,但是如果1000001,1000002,1000003之类的序列你这么开数组不是太多空间了?并且前面也要遍历很多无用的次数。 所以我们在**设计具体算法的时候**,先找到最小值min,再找最大值max。然后创建这个区间大小的数组,从min的位置开始计数,这样就可以最大程度的压缩空间,提高空间的使用效率。 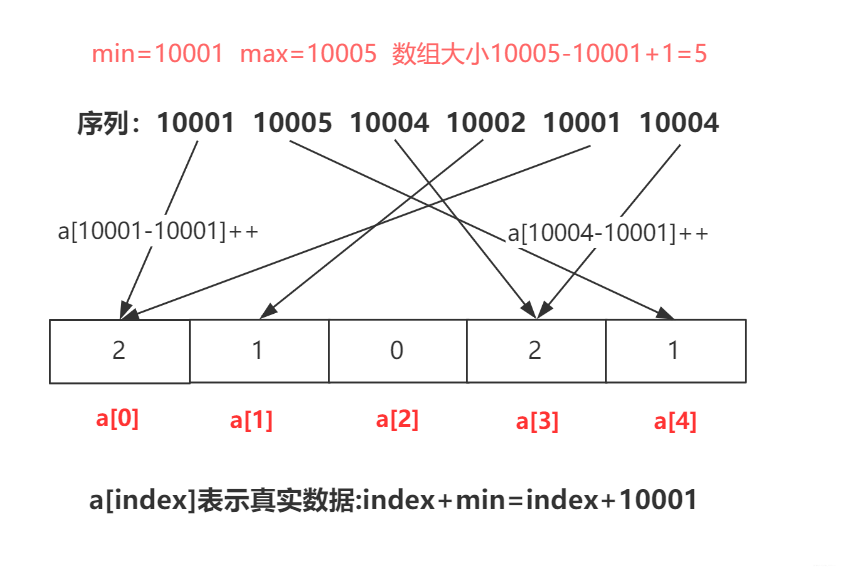 ## 代码实现 通过上述分析,计数排序的实现代码为: ```java import java.util.Arrays; public class test { public static void jishusort(int a[]) { int min=Integer.MAX_VALUE;int max=Integer.MIN_VALUE; for(int i=0;i<a.length;i++)//找到max和min { if(a[i]<min) min=a[i]; if(a[i]>max) max=a[i]; } int count[]=new int[max-min+1];//对元素进行计数 for(int i=0;i<a.length;i++) { count[a[i]-min]++; } //排序取值 int index=0; for(int i=0;i<count.length;i++) { while (count[i]-->0) { a[index++]=i+min;//有min才是真正值 } } } public static void main(String[] args) { int a[]= {6,1,6,9,9,1,4,2,1,5,8,8}; jishusort(a); System.out.println(Arrays.toString(a)); } } ``` 打印结果为: >[1, 1, 1, 2, 4, 5, 6, 6, 8, 8, 9, 9] ## 结语 通过上面我想计数排序你已经搞得很清楚了,计数排序的时间复杂度为O(n+k)其中k为正数范围;线性时间大部分都比其他排序快一点,但是也不一定,例如你遇到`1 2 4 2 100001`这样一个序列,其中k的范围为10000,虽然他是`O(n+k)=O(k)`k远大于n情况,但是此时`O(k)>O(nlogn)`因为n太小,而K太大,需要遍历的词数太多了。 所以即使计数排序它是线性但是并非所有情况都是最好的方法,并且也占用了太多内存。当数据范围波动不是很大,数据相对比较集中,这时候用计数排序肯定是最好的啦,这点和桶排序的要求很像哦,没错,它其实就是一种特殊的桶排序,他的桶大小为1,用数值计数词数而以,其他都是一样的操作。 此时**bigsai**沾沾自喜终于讲完了,在旁边的**pigpian**和**doudou**直呼:讲的真的太好了,我不光要把它**收藏下来**,我还要给你**点赞**! **bigsai笑了**,心想光点赞哪里够🤭,**阴森森的冲着两个少女**……说到:点赞收藏哪里够,公众号也顺便一波:`bigsai` 关注一波,后面还会讲其他的。 ## 结语 原创不易,最后我请你帮两件事帮忙一下: 1. star支持一下, 您的肯定是我在csdn创作的源源动力。 2. 微信搜索「**bigsai**」,关注我的公众号,不仅免费送你电子书,我还会第一时间在公众号分享知识技术。加我还可拉你进力扣打卡群一起打卡LeetCode。 记得关注、咱们下次再见!  【排序】交换类排序—冒泡排序、快速排序手撕图解 【排序算法】手写堆排序