二叉查找树 agile Posted on Jul 14 2023 数据结构与算法 yukiyama --- title: 二叉查找树 tags: - 树 - 二叉查找树 - 算法与数据结构 categories: 算法与数据结构 description: >- 对于一棵二叉树,每个结点存有一个可用于比较的数据项,规定结点 x 的左子树中所有结点的数据项小于 x 的数据项,而 x 的右子树中所有结点的数据项大于 x 的数据项,这样的二叉树即为二叉查找树。本文于展现如何设计一个二叉查找树类,分析主要方法的代码实现,并给出该类的完整实现代码。 cover: >- https://raw.githubusercontent.com/iyukiyama/pics/master/hexo-iyukiyama/site_img/posts/algorithms/bst-bg.png katex: true abbrlink: binary-search-tree keywords: top_img: comments: --- # 二叉查找树 (树ADT连载 3/13) > - 可在作者的 [github仓库](https://github.com/iyukiyama/leetcode-posts) 中获取本文和其他文章的 markdown 源文件及相关代码。 > > - 欢迎评论或仓库 PR 指出文章错漏或与我讨论相关问题,我将长期维护所有文章。 > - 所有文章均用 Typora 完成写作,可使用 Typora 打开文章 md 文件,以获得最佳阅读体验。 🌲🌲🌲 **一起手写一棵完整的二叉查找树。** ❗️ **【NEW】** ❗️ - 9-15: [红黑树从入门到看开](https://leetcode.cn/circle/discuss/SwgIJV/) 这是小白 yuki 推出的「树ADT」系列文章的第 3 篇 (3/13) 。 *** 实际上本文是为了后续讲解多种 **平衡二叉树** 的前置文章,最终目的是讲解 **「红黑树」** (已推出,[红黑树从入门到看开](https://leetcode.cn/circle/discuss/SwgIJV/))。 本文重点在于展现如何设计一个 BST 类,分析主要方法的代码实现,并给出该类的完整实现代码。读者学习之后 **可以自己写出一个方法较为完备的基本 BST 类** 。 *** yuki的其他文章如下,欢迎阅读指正! > 如下所有文章同时也在我的 github [仓库](https://github.com/iyukiyama/leetcode-posts) 中维护。 | 文章 | [发布时间] 字数/览/藏/赞 (~2022-10-20) | | ------------------------------------------------------------ | ---------------------------------------- | | [十大排序从入门到入赘](https://leetcode.cn/circle/discuss/eBo9UB/) 🔥🔥🔥 | [20220516] 2.5万字/64.8k览/3.7k藏/937赞 | | [二分查找从入门到入睡](https://leetcode.cn/circle/discuss/ooxfo8/) 🔥🔥🔥 | [20220509] 2.3万字/38.4k览/2.1k藏/503赞 | | [并查集从入门到出门](https://leetcode.cn/circle/discuss/qmjuMW/) 🔥🔥 | [20220514] 1.2万字/17.9k览/1.0k藏/321赞 | | [图论算法从入门到放下](https://leetcode.cn/circle/discuss/FyPTTM/) 🔥🔥 | [20220617] 5.6万字/19.9k览/1.3k藏/365赞 | | 树ADT系列 (预计13篇) | 系列文章,连载中 | | 3. [二叉查找树](https://leetcode.cn/circle/discuss/wPzlSb/) | [20220801] 5千字 | | 4. [AVL树](https://leetcode.cn/circle/discuss/zbwD3p/) | [20220817] 5千字 | | 5. [splay树](https://leetcode.cn/circle/discuss/BCK17f/) | [20220817] 5千字 | | 6. [红黑树从入门到看开](https://leetcode.cn/circle/discuss/SwgIJV/) 🔥🤯🤯🤯 | [20220915] 3万字/5.3k览/269藏/72赞 | | 10. [树状数组从入门到下车](https://leetcode.cn/circle/discuss/qGREiN/) 🔥🤯 | [20220722] 1.4万字/5.8k览/196藏/72赞 | | 11. [线段树从入门到急停](https://leetcode.cn/circle/discuss/H4aMOn/) 🔥🤯 | [20220726] 2.5万字/8.7k览/481藏/138赞 | | [图论相关证明系列](https://leetcode.cn/circle/discuss/GV0JrV/) | 系列文章 | | 1. [Dijkstra正确性证明](https://leetcode.cn/circle/discuss/jJQn7V/) 🤯 | [20220531] | | 2. [Prim正确性证明](https://leetcode.cn/circle/discuss/VVEc8f/) 🤯 | [20220919] | | 3. [Bellman-Ford及SPFA正确性证明](https://leetcode.cn/circle/discuss/xeEwYl/) | [20220602] | | 4. [Floyd正确性证明](https://leetcode.cn/circle/discuss/Nbzix4/) | [20220602] | | 5. [最大流最小割定理证明](https://leetcode.cn/circle/discuss/tMIy36/) 🤯🤯 | [20220719] | | 6. [Edmonds-Karp复杂度证明](https://leetcode.cn/circle/discuss/tN3sZc/) 🤯🤯 | [20220515] | | 7. [Dinic复杂度证明](https://leetcode.cn/circle/discuss/T9Xa1R/) 🤯🤯 | [20220531] | *** [TOC] *** ## 二叉查找树 [二叉查找树 / 二叉搜索树 / 二叉排序树 (Binary Search Tree / Binary Sort Tree, BST) ](https://en.wikipedia.org/wiki/Binary_search_tree): 对于一棵二叉树,每个结点存有一个可用于比较的数据项,规定结点 $x$ 的左子树中所有结点的数据项小于 $x$ 的数据项,而 $x$ 的右子树中所有结点的数据项大于 $x$ 的数据项,这样的二叉树即为二叉查找树。对于有 $n$ 个元素的二叉树,假设树高平衡,则根据前面的性质可知其高度为 $logn$ ,我们将能够通过其结点数据项有序的特点,以类似二分查找的树上的 **二分操作** 实现 $O(logn)$ 平均时间复杂度的插入,查找和删除等操作。BST 内容非常丰富,下面我们先介绍非自平衡的 **基本 BST** ,由于基本BST树高不保证平衡,树上操作的复杂度无法保证为 $O(logn)$ ,因此引入 **平衡 BST** 。我们将会详细几种不同的平衡 BST 实现。 根据定义可知下图中只有左侧的树是 BST ,右侧的树中结点 7 与 6 不满足 BST 的结点顺序性质,若结点 7 是结点 8 的左子结点,则为 BST。 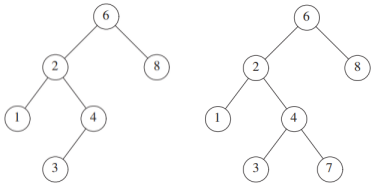 ※ 应用二叉查找树实现的数据结构一般为 $set$ 或 $map$,若为 $set$ (例如 Java 中的 $TreeSet$),则不会存储相同数据项,若为 $map$ (例如 Java 中的 $TreeMap$),则不会存储相同 $key$ 值。若要求保存相同值,可以采用链表或将相同值看作小于或大于来处理,本文以及后续讲解的所有二叉查找树均不保存相同值。 > 根据 Wiki 词条,此数据结构在 1960 年代由多人独立提出。 > > The binary search tree algorithm was discovered independently by several researchers, including P.F. Windley, [Andrew Donald Booth](https://en.wikipedia.org/wiki/Andrew_Donald_Booth), [Andrew Colin](https://en.wikipedia.org/wiki/Andrew_Colin), [Thomas N. Hibbard](https://en.wikipedia.org/wiki/Thomas_N._Hibbard). <br /> ### 基本BST 基本 BST 即只保持 BST 结点数据项大小关系性质,而不维护树高平衡的 **非平衡 BST** 。所谓「平衡」,指树的形态类似等腰三角形,从根结点到任意叶子结点的路径长度都是稳定的 $O(logn)$ ,更严格的定义是 **「任意结点的左右子树高差不超过 1」** ,如此即能保证对结点的增删改查的时间复杂度均为 $O(logn)$ 。 基本BST的定义十分简单,我们直接给出它的类的实现架构,并介绍其中的主要方法,然后再分析主要操作的时空复杂度。 > 本节内容为 Mark Allen Weiss 所著 [数据结构与算法分析:Java语言描述](https://awesome-programming-books.github.io/algorithms/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95%E5%88%86%E6%9E%90%EF%BC%9AJava%E8%AF%AD%E8%A8%80%E6%8F%8F%E8%BF%B0.pdf) 相关章节的整理和总结。代码亦来自该书,略作改动。 <br /> #### 基本BST类架构 以下是基本 BST 类 ($MyTreeSet$) 架构。 | 类成员/方法 | 描述 | | ------------------------------------------ | ----------------------------------- | | `private Node<E> root` | 唯一字段,根结点 | | `public MyTreeSet()` | 无参构造器 | | `public void clear()` | 树置空 | | `public boolean isEmpty()` | 树判空 | | `public void add(E e)` | 插入结点驱动方法 | | `public void remove(E e)` | 删除结点驱动方法 | | `public E first()` | 查找最小结点驱动方法 | | `public E last()` | 查找最大结点驱动方法 | | `public E floor(E e)` | 查找小于等于 $e$ 的最大元素驱动方法 | | `public E ceiling(E e)` | 查找大于等于 $e$ 的最小元素驱动方法 | | `public E lower(E e)` | 查找严格小于 $e$ 的最大元素驱动方法 | | `public E higher(E e)` | 查找严格大于 $e$ 的最小元素驱动方法 | | `public boolean contains(E e)` | 结点存在判定驱动方法 | | `public void printTree()` | 中序遍历打印树的驱动方法 | | `public int size()` | 求树大小驱动方法 | | `public int height()` | 求树高驱动方法 | | `private Node<E> add(E e, Node<E> t)` | 插入结点 | | `private Node<E> remove(E e, Node<E> t)` | 删除结点(懒惰删除) | | `private Node<E> first(Node<E> t)` | 返回树的最小结点 | | `private Node<E> last(Node<E> t)` | 返回树的最大结点 | | `private Node floor(Node<E> x, E e)` | 查找小于等于 $e$ 的最大元素 | | `private Node<E> ceiling(Node<E> x, E e)` | 查找大于等于 $e$ 的最小元素 | | `private Node lower(Node<E> x, E e)` | 查找严格小于 $e$ 的最大元素 | | `private Node<E> higher(Node<E> x, E e)` | 查找严格大于 $e$ 的最小元素 | | `private boolean contains(E e, Node<E> t)` | 判断树中是否有指定元素的结点 | | `private void printTree(Node<E> t)` | 中序遍历打印树 | | `private int height(Node<E> t)` | 求以 $t$ 为根结点的树高 | | `private int size(Node<E> t)` | 求以 $t$ 为根结点的树大小 | <br /> 以下是二叉树结点嵌套类 $Node$ 的架构。 | 类成员/方法 | 描述 | | ----------------------------------------------------- | -------- | | `public E element` | 结点数据 | | `public Node<E> left` | 左子结点 | | `public Node<E> right` | 右子结点 | | `public Node(E element)` | 构造器 | | `public Node(E element, Node<E> left, Node<E> right)` | 构造器 | <br /> #### 主要方法 在类架构表格中,我们看到 BST 实现的 $set$ 类 ($MyTreeSet$) 主要应该包含哪些方法,接下来我们讲解这其中的主要方法。其他实现简单的方法在「类的实现代码」中呈现。 <br /> ##### add 插入结点操作由插入驱动方和具体插入方法完成,将值为 $e$ 的结点插入到当前二叉树中并使得插入后仍保持查找树性质。递归地比较 $e$ 和当前结点值的大小,最后 $e$ 总能 **作为一个叶子结点** 被插入到满足查找树性质的位置。 对于具体插入方法,当原树为 $null$ 时返回 `Node<>(e,null, null)` 给 $root$ ,即数据为 $e$ 的结点作为根结点插入。当原树不为 $null$ 时, **插入后返回原根** 。 ```java public void add(E e) { // 插入结点驱动方法 root = add(e, root); } private Node<E> add(E e, Node<E> t){ // 插入结点 if(t == null) return new Node<>(e,null, null); int cmp = e.compareTo(t.element); if(cmp < 0) t.left = add(e, t.left); // 递进直到t.left == null else if(cmp > 0) t.right = add(e, t.right); // 递进直到t.right == null return t; // 等于时不插入(以该树只能存放不同的元素为前提) } ``` <br /> ##### remove 删除结点操作由删除驱动方法和具体删除方法完成,将数据项为 $e$ 的结点删除并使得删除后仍保持查找树性质。 首先,在驱动方法中执行 $contains(e)$ ,若不存在直接返回,否则删除目标存在,调用具体删除方法,递归地寻找 $element$ 为 $e$ 的结点 $t$ ,对其执行 **懒惰删除** 。删除相比其他操作要复杂一些,以下为找到时结点 $t$ 的两种情形。 - 情形1: $t$ 有左右两个子结点。 - 情形2: $t$ 有一个或没有子结点。 情形1时,找到 $t$ 的右子树中最小结点 $min$ ,令 `t.element = min.element` ,即相当于用 $min$ 替换掉要删除的 $t$ ,然后对右子树执行删除 $min$ 的操作(由于是最小值,故此删除必属于情形 2)。 情形2时,根据是否有左子结点,执行此语句 `t = (t.left != null) ? t.left : t.right` 。有左子结点时 `t = t.left`,即用这个左子结点取代 $t$。没有左子结点时 `t = t.right`,表示以右子结点取代 $t$(包含右子结点也为空的情形,则此时 `t = null`)。 对于具体删除方法,当原树为 $null$ 时返回 $t$ (即 $root$ ) 给 $root$ 。当原树不为 $null$ 时,在删除后递归地返回到当前根给 $root$(例如当树只有根结点,且删除的就是该根时,`root = null` )。 ```java public void remove(E e) { // 删除结点驱动方法 if (e == null) throw new IllegalArgumentException("argument to remove() is null"); if (!contains(e)) return; // 检测删除目标是否存在 root = remove(e, root); } private Node<E> remove(E e, Node<E> t){ // 懒惰删除结点 if(t == null) return null; int cmp = e.compareTo(t.element); if(cmp < 0) t.left = remove(e, t.left); // 递归地在左侧寻找 else if(cmp > 0) t.right = remove(e, t.right); // 递归地在右侧寻找 // e等于t.element,分两种情形 else if(t.left != null && t.right != null) { // 情形1:该t的左右子节点均不为null t.element = first(t.right).element; // 在右子树中找min t.right = remove(t.element, t.right); // 此时min已是t.element,必为情形2 } else t = (t.left != null) ? t.left : t.right; // 情形2: 1以外的情形 return t; } ``` <br /> ##### first/last 查找具有最小/最大数据的结点的操作由驱动方法和具体方法实现。根据 BST 性质一直向左/向右寻找即可找到最小/最大值。以下以递归方式实现 $first$,以迭代方式实现 $last$ 。这两个方法的实现容易理解,不赘述。如下展示 $first$ 的实现,$last$ 的实现请看「类的实现代码」。 ```java public E first() { // 查找最小结点驱动方法 if(isEmpty()) throw new NoSuchElementException(); return first(root).element; } private Node<E> first(Node<E> t){ // 返回树的最小节点(尾递归方式) if(t.left == null) return t; return first(t.left); } ``` <br /> ##### floor/ceiling $floor$ 方法用于查找小于等于指定元素中的最大者,$ceiling$ 方法用于查找大于等于指定元素中的最小者,均由驱动方法和具体方法实现。其实现方式也是根据 BST 性质向左/向右寻找目标。 以 $floor$ 为例,说明如下。 1. `if (cmp == 0) return x;` 若当前元素 $x$ 与目标元素相等,则 $x$ 即为所求直接返回。 2. `if (cmp < 0) return floor(x.left, e);` 若 $e$ 小于当前元素 $x$,说明目标元素在 $x$ 的左子树中,传入 $x.left$ 递归调用 $floor$ 。 3. `Node<E> t = floor(x.right, e);` 否则此时 $e$ 大于 $x$ ,在 $x$ 的右子树中找最大者,即为所求。 如下展示 $floor$ 的实现,$ceiling$ 的实现请看「类的实现代码」。 ```java public E floor(E e) { // 查找小于等于 e 的最大元素驱动方法 if (e == null) throw new IllegalArgumentException("argument to floor() is null"); if (isEmpty()) throw new NoSuchElementException("calls floor() with empty symbol table"); Node<E> x = floor(root, e); if (x == null) throw new NoSuchElementException("argument to floor() is too small"); else return x.element; } private Node floor(Node<E> x, E e) { // 小于等于 e 中最大者 if (x == null) return null; int cmp = e.compareTo(x.element); if (cmp == 0) return x; if (cmp < 0) return floor(x.left, e); Node<E> t = floor(x.right, e); if (t != null) return t; else return x; } ``` 类似地,$lower$ 方法用于查找严格小于指定元素中的最大者,$higher$ 方法用于查找严格大于指定元素的最小者。二者的实现方式与 $floor/ceiling$ 非常类似,只需要将等于的情形与需要递归的情形合写即可,具体请看「类的实现代码」。 <br /> ##### contains 寻找树中是否包含数据项为 $e$ 的结点的操作由相应的驱动方法和具体方法实现。根据二叉查找树的性质以递归方式一直向左/向右寻找。找到返回 $true$ ,否则返回 $false$ 。 ```java public boolean contains(E e) { // 判断是否包含值为e的元素的结点的驱动方法 return contains(e, root); } private boolean contains(E e, Node<E> t) { // 判断树中是否有指定元素的节点 if(t == null) return false; int cmp = e.compareTo(t.element); if(cmp < 0) return contains(e, t.left); else if(cmp > 0) return contains(e, t.right); else return true; } ``` <br /> #### 时空复杂度 二叉查找树的平均深度为 $O(logn)$ ,因此上述介绍的主要方法 **平均时间复杂度** 均为 $O(logn)$ 。当树为链状时,退化为链表形式,达到最坏时间复杂度 $O(n)$ 。若方法以递归实现,则空间复杂度取决于递归深度 $O(logn)$ ,若以迭代方式实现则空间复杂度为 $O(1)$ 。 | 方法 | 平均时间 | 最坏时间 | | --------------------------------------------------------- | --------- | -------- | | add/remove/first/last/floor/ceiling/lower/higher/contains | $O(logn)$ | $O(n)$ | > BST 平均深度为 $O(logn)$ 的证明见此[论文](http://luc.devroye.org/devroye_reed_1995_variance_height_random_binary_search_tree.pdf)。 <br /> #### 类的实现代码 ```java /** * 二叉查找树类 MyTreeSet */ class MyTreeSet<E extends Comparable<? super E>>{ private Node<E> root; // 唯一字段,根节点 public MyTreeSet() {} // 无参构造器 public void clear() { // 树置空 root = null; } public boolean isEmpty() { // 判树空 return root == null; } public void add(E e) { // 插入结点驱动方法 root = add(e, root); } public void remove(E e) { // 删除结点驱动方法 if (e == null) throw new IllegalArgumentException("argument to remove() is null"); if (!contains(e)) return; // 检测删除目标是否存在 root = remove(e, root); } public E first() { // 查找最小结点驱动方法 if(isEmpty()) throw new NoSuchElementException(); return first(root).element; } public E last(){ // 查找最大结点驱动方法 if(isEmpty()) throw new NoSuchElementException(); return last(root).element; } public E floor(E e) { // 查找小于等于 e 的最大元素驱动方法 if (e == null) throw new IllegalArgumentException("argument to floor() is null"); if (isEmpty()) throw new NoSuchElementException("calls floor() with empty symbol table"); Node<E> x = floor(root, e); if (x == null) throw new NoSuchElementException("argument to floor() is too small"); else return x.element; } public E ceiling(E e) { // 查找大于等于 e 的最小元素驱动方法 if (e == null) throw new IllegalArgumentException("argument to ceiling() is null"); if (isEmpty()) throw new NoSuchElementException("calls ceiling() with empty symbol table"); Node<E> x = ceiling(root, e); if (x == null) throw new NoSuchElementException("argument to ceiling() is too large"); else return x.element; } public E lower(E e) { // 查找严格小于 e 的最大元素驱动方法 if (e == null) throw new IllegalArgumentException("argument to lower() is null"); if (isEmpty()) throw new NoSuchElementException("calls lower() with empty symbol table"); Node<E> x = lower(root, e); if (x == null) throw new NoSuchElementException("argument to lower() is too small"); else return x.element; } public E higher(E e) { // 查找严格大于 e 的最小元素驱动方法 if (e == null) throw new IllegalArgumentException("argument to higher() is null"); if (isEmpty()) throw new NoSuchElementException("calls higher() with empty symbol table"); Node<E> x = higher(root, e); if (x == null) throw new NoSuchElementException("argument to higher() is too large"); else return x.element; } public boolean contains(E e) { // 判断是否包含值为e的元素的结点的驱动方法 return contains(e, root); } public void printTree() { // 中序遍历打印 if (isEmpty()) System.out.println("Empty tree"); else printTree(root); } public int size() { // 求树的个数驱动方法 return size(root); } public int height() { // 求树的高度驱动方法 return height(root); } private Node<E> add(E e, Node<E> t){ // 插入结点 if(t == null) return new Node<>(e,null, null); int cmp = e.compareTo(t.element); if(cmp < 0) t.left = add(e, t.left); // 递进直到t.left == null else if(cmp > 0) t.right = add(e, t.right); // 递进直到t.right == null return t; // 等于时不插入(以该树只能存放不同的元素为前提) } private Node<E> remove(E e, Node<E> t){ // 懒惰删除结点 if(t == null) return null; int cmp = e.compareTo(t.element); if(cmp < 0) t.left = remove(e, t.left); // 递归地在左侧寻找 else if(cmp > 0) t.right = remove(e, t.right); // 递归地在右侧寻找 // e等于t.element,分两种情形 else if(t.left != null && t.right != null) { // 情形1:该t的左右子节点均不为null t.element = first(t.right).element; // 在右子树中找min t.right = remove(t.element, t.right); // 此时min已是t.element,必为情形2 } else t = (t.left != null) ? t.left : t.right; // 情形2: 1以外的情形 return t; } private Node<E> first(Node<E> t){ // 返回树的最小节点(尾递归方式) if(t.left == null) return t; return first(t.left); } private Node<E> last(Node<E> t){ // 返回树的最大节点(循环方式) while(t.right != null) t = t.right; return t; } private Node floor(Node<E> x, E e) { // 小于等于 e 中最大者 if (x == null) return null; int cmp = e.compareTo(x.element); if (cmp == 0) return x; if (cmp < 0) return floor(x.left, e); Node<E> t = floor(x.right, e); if (t != null) return t; else return x; } private Node<E> ceiling(Node<E> x, E e) { // 大于等于 e 中的最小者 if (x == null) return null; int cmp = e.compareTo(x.element); if (cmp == 0) return x; if (cmp > 0) return ceiling(x.right, e); Node<E> t = ceiling(x.left, e); if (t != null) return t; else return x; } private Node lower(Node<E> x, E e) { // 小于 e 中最大者 if (x == null) return null; int cmp = e.compareTo(x.element); if (cmp <= 0) return lower(x.left, e); Node<E> t = lower(x.right, e); if (t != null) return t; else return x; } private Node<E> higher(Node<E> x, E e) { // 大于 e 中的最小者 if (x == null) return null; int cmp = e.compareTo(x.element); if (cmp >= 0) return higher(x.right, e); Node<E> t = higher(x.left, e); if (t != null) return t; else return x; } private boolean contains(E e, Node<E> t) { // 判断树中是否有指定元素的节点 if(t == null) return false; int cmp = e.compareTo(t.element); if(cmp < 0) return contains(e, t.left); else if(cmp > 0) return contains(e, t.right); else return true; } private void printTree(Node<E> t) { // 中序遍历打印树 if(t != null) { printTree(t.left); System.out.println(t.element); printTree(t.right); } } private int height(Node<E> t) { // 返回以t为根节点的树的高度 if(t == null) return -1; else return 1 + Math.max(height(t.left), height(t.right)); } private int size(Node<E> t) { // 递归地遍历树的所有节点,返回节点总数 if(t != null) { if(t.left != null && t.right != null) { return 1 + size(t.left) + size(t.right); } else { return t.left != null ? 1 + size(t.left) : 1 + size(t.right); } } return 0; } /** * 二叉树节点嵌套类 */ private static class Node<E>{ public E element; public Node<E> left, right; public Node(E element, Node<E> left, Node<E> right){ this.element = element; this.left = left; this.right = right; } } } ``` <br /> #### 测试代码 ```java package com.yukiyama; import java.util.NoSuchElementException; public class MyTreeSetDemo { public static void main(String[] args) { MyTreeSet<Integer> t = new MyTreeSet<>( ); // 10 98 61 13 8 20 48 29 47 74 /* * 10 * 8 98 * 61 * 13 74 * 20 * 48 * 29 * 47 */ int[] elements = {10,98,61,13,8,20,48,29,47,74}; for(int e : elements) t.add(e); t.add(10); t.printTree(); // 输出8 10 13 20 29 47 48 61 74 98 System.out.printf("size: %d, height: %d, min: %d, max: %d\n", t.size(), t.height(), t.first(), t.last()); System.out.printf("has 47? %s, has 100? %s\n", t.contains(47), t.contains(100)); System.out.printf("floor(9): %s, floor(10): %s, ceiling(73): %s, ceiling(98): %s\n", t.floor(9), t.floor(10), t.ceiling(73), t.ceiling(98)); System.out.printf("lower(9): %s, lower(10): %s, higher(73): %s, higher(61): %s\n", t.lower(9), t.lower(10), t.higher(73), t.higher(61)); t.remove(47); t.remove(48); t.remove(61); t.printTree(); System.out.println("is empty: " + t.isEmpty()); // 输出false t.clear(); System.out.println("is empty: " + t.isEmpty()); // 输出true System.out.printf("size: %d, height: %d\n", t.size(), t.height());// 输出0 } } ``` <br /> 二分查找从入门到入睡 并查集从入门到出门