0912学习 agile Posted on Sep 11 2023 面试 unity基础 lua ##Lua的基本类型 --- - 简单变量类型: - `number`:数字类型,所有的数字都是number类型,内部实现中区分为整形和浮点型。 - `string`:字符串类型 , “xxx” 或 ‘xxx’ - `boolean` 布尔类型 , true 或 false - `nil` 空类型 , 未声明的变量均为nil类型 - 复杂变量类型: - `function`:函数类型, 函数存储在变量中 可以作为函数参数和返回值或存储在表中。 - `C Function` - `Lua Function` - `light C Function` - `userdata`:用户自定义数据类型 , 表示任意存储在变量中的C数据结构 - `userdata` - `light userdata`:他是一个`void *`指针,不受垃圾管理器管理,他没有元表 - `table`:表类型,类似字典的一种关联数组,索引为数字或字符串,利用{}创建表 - `thread`:lua中的协程 `string`, `lua function`, `userdata`, `thread`和`table`这些可以被`垃圾回收管理`的类型 --- ##注释符 --- - `单行注释`:两个连续的连字符(`--`) - `长注释或多行注释`:两个连续的连字符加两对连续左方括号(`--[[ ]]`) --- ##Boolean --- - Boolean值`false`和`nil`之外的所有值都视为`真` - `零`和`空字符串`也视为`真` --- ###逻辑运算符and or not --- - 逻辑运算符`and`运算结果为:如果它的`第一个`操作数为`假`,返回`第一个操作数`,`否则`返回`第二个操作数` - 逻辑运算符`or`运算结果为:如果它的`第一个`操作数不为`假`,返回`第一个`操作数,`否则`返回`第二个`。 --- ```lua --5 print(4 and 5) --nil print(nil and 13) --false print(false and 12) --6 print(" " and 6) --0 print(0 or 5) --hello print(false or "hello") --false print(nil or false) ``` --- ####短路取值 --- - `x = x or v `等价于:`if not x then x = v end` - `a and b or c`:等价于C语言的三目运算符`a?b:c` - lua中没有三目运算符 --- ```lua local x = 3 x = x or 4 y = 2; --3 print(x) --2 print(x > y and y or x) ``` --- ##数值 --- - lua5.2及之前的版本中,所有的数值都以双精度浮点格式表示 - 从5.3版本开始,Lua为数值提供了俩种选择:`integer的64位整型`和被称为`float的双精度浮点型` --- ```lua local num = 100 --利用type(变量名)可以返回当前变量的类型名 (返回值类型是string) print("num:", type(num)) --在少数情况下,当需要区分整型值和浮点值时,可以使用math.type print("math num type:", math.type(num)) print("math num type:",math.type(3.09)) ``` --- - `floor除法`会对得到的`商向负无穷取整`,从而保证结果是一个整数 - 取模公式:`a % b == a - ((a // b) * b)` - 对于任意指定的`正常量K`,即使`x是负`数,表达式 `x%K`的结果也永远在`[0,k-1]`之间 --- ```lua --Lua中使用//表示为地板除,数学库中的math.floor()向下取整的效果是一样 --对一个数进行除法运算后向下取整 --3//2 1 print("3//2", 3 // 2) --3/2 1.5 print("3/2", 3 / 2) --1 print("math.floor:", math.floor(3 / 2)) --3 print("math.floor:", math.floor(3.5)) --表达式 i % 2 结果均为 0 或 1 --1 print(9 % 2) --0 print(12 % 2) --判断A 是否大于或小于B --A % B ,如果A 小于等于B ,其结果是 A --9 print(9 % 11) --X 保留 N位小数:x-x%0.01 恰好是x保留两位小数的结果 local x = 10.1234 --10.12 print(x - x % 0.01) --10.1 print(x - x % 0.1) --任意范围的角度归一化到 [0,2Π) print(360 % (2 * math.pi)) -- -10 % 3 = -10 - floor(-10 / 3) *3 = -10 - (-4) * 3 = -10 + 12 = 2 --2 print(-10 % 3) --math.floor():向负无限取整 --将数值X 向最近的整数取整,可以对x+0.5调用math.floor()函数 local x = 2.1; --2 print(math.floor(x + 0.5)) x = 2.5 --3 print(math.floor(x + 0.5)) --math.ceil向正无限取整 --3 print(math.ceil(x)) --11 print(math.ceil(10.1)) --math.modf() 向零取整 拆分成商和余数 -- 10 0.2 print(math.modf(10.2)) -- -10 -0.2 print(math.modf(-10.2)) --当不带参数调用时,该函数将返回一个在 [0,1)范围内均匀分布的伪随机整数 print(math.random()) --当带有一个整型值n的参数调用时,该函数将返回一个在[0,n)范围内均匀分布的伪随机整数 print(math.random(10)) --当带有两个整型值 L 和 U 的参数调用时,该函数返回在[L,U]范围内的伪随机整数 print(math.random(20, 30)) --通过增加0.0 的方法将整型值强制转换为浮点型值,一个整型值总是可以被转换成浮点型值 x = -3 --integer print(math.type(x)) x = x + 0.0 --float print(math.type(x)) --数值强转为整型值 ---3 print(math.tointeger(x)) ``` --- ##字符串 - 字符使用8个比特位来存储 - 字符串是不可变值 - Lua语言会负责字符串的分配和释放 - 长度操作符 (`#`) 获取字符串的长度 - 使用连接操作符`..`(两个点)来进行字符串连接 - 双引号和单引号声明字符串是`等价`的。它们二者唯一的区别在于,使用双引号声明的字符串中出现单引号时,单引号不用转义;使用单引号声明的字符串中出现双引号时,双引号可以不用转义 - 使用一对`双方括号`来声明长字符串/多行字符串常量 - 被方括号括起来的内容可以包括很多行,并且内容中的转义序列`不会被转义` --- ###模式匹配 --- - `.`:任意字符 - `%a`:**字母** - `%c`:控制字符 - `%d`:**数字** - `%g`:除空格以外的可打印字符 - `%l`:**小写字母** - `%p`:标点符号 - `%s`:**空白字符** - `%u`:**大写字母** - `%w`:**字母和数字** - `%x`:十六进制数字 - `%A`:**任意非字母的字符**,大小形式表示对应的补集 - `%?`:匹配一个问号 - `%%`:匹配一个百分号 - `[]`:字符集,`[%w_]`匹配字母和数字以及下划线,`[%[%]]`匹配方括号,`[0-9a-fA-F]` 相当于`%x` - `^`:在字符集前面加`^`就可以得到这个字符集的补集。`[^\n]`匹配换行符以外的其他所有字符 - `+`:重复一次或多次 - `*`:重复零次或多次 - `-`:重复零次或多次(最小匹配) - `?`:出现0次或1次 --- ###string方法 --- ```C# --显式地将一个字符串转换成数值 --当这个字符串的内容不能表示为有效数字时该函数返回nil; --否则,该函数就按照Lua语法扫描器的规则返回对应的整型值或浮点类型值: --10.1 print(tonumber(" 10.1")) --nil print(tonumber("10.e")) --默认情况下,函数tonumber使用的是十进制,但是也可以指明使用二进制到三十六进制之间的任意进制 --37 print(tonumber("100101", 2)) --将数值转换成字符串 --true print(tostring(23) == "23") --返回字符串s的长度,等价于 #s --4 print(#"1234") --4 print(string.len("1234")) --返回将字符串s重复n次的结果 --abc-abc print(string.rep("abc", 2, "-")) --abcabc print(string.rep("abc", 2)) --用于字符串翻转 --cba print(string.reverse("abc")) --abc print(string.lower("ABC")) --ABC print(string.upper("abc")) --从字符串s中提取第i个到第j个字符(包括第i个 和 第j个字符,字符串的第一个字符索引为1); --该函数支持负数索引。负数索引从字符串的结尾开始技数:索引-1代表字符串的最后一个字符,索引-2代表倒数第二个字符 --o,world! print(string.sub(s, 5)) --hello,world! print(string.sub(s, 1, -1)) --hello,world! print(string.sub(s, 1, #s)) --ello,world print(string.sub(s, 2, -2)); --接收零个或多个整数作为参数,然后将每个整数转换成对应的字符,最后返回由这些字符连接而成的字符串 print(string.char()) --abc print(string.char(97,98,99)) s = "abc" --返回字符串s中第1个字符的内部数值表示,第二个参数是可选的 --97 print(string.byte(s)) --97 print(string.byte(s, 1)) --97 98 99 print(string.byte(s, 1, -1)) --97 98 print(string.byte(s, 1, 2)) --指定的字符串中进行模式搜索 --如果该函数在指定的字符串中找到了匹配的模式,则返回模式的开始和结束位置,否则返回nil --7 9 print(string.find("hello world!","wor")) --nil print(string.find("Hello,world!","wor2")) local s = "Hello12345World" --6 10 print(string.find(s, "%d+")) --string.match返回的是目标字符串中与模式相匹配的那部分子串,并不是该模式所在的位置 --12345 print(string.match(s, "%d+")) s = "Hello world!"; --则把所有匹配的模式用另一个字符串替换 该函数的第二个返回值中返回发生替换的次数 --He..o wor.d! 3 print(string.gsub(s, "l", ".")) --gsub还有可选的第四个参数,可以限制替换的次数 --开始限制替换次数 --He*lo world! 1 print(string.gsub(s, "l", '*', 1)) --__llo world! 1 print(string.gsub(s, "He", "__")) --He__o world! 1 print(string.gsub(s, "ll", "__")) --Hello world! 0 print(string.gsub(s, "A", "C")) local replaceStr = function(str) return "[" .. string.upper(str) .. "]" end --一个函数,该函数的参数是被匹配的字符串,该函数的返回值将会作为目标字符串去进行替换匹配的内容 --He[L][L]o wor[L]d! 3 print(string.gsub(s, "l", replaceStr)) local replaceTable = { ['l'] = 2 } --gsub的第三个参数是一个table,也就是说,当gsub的第三个参数是一个table时, --如果在查找的字符串中有与第二个参数相匹配的内容,就会将该内容作为key, --在table中查找该key对应的value;如果该table中没有这个key,则不进行替换 --He22o wor2d! 3 print(string.gsub(s, 'l', replaceTable)) --使用find来实现一个我们自己的gmatch,功能和gmatch是差不多的 local SGMatch = function(world, pattern) local returnTable = {} local i, j = string.find(world, pattern) local index = 0 while i do returnTable[#returnTable + 1] = string.sub(world, i, j) i, j = string.find(world, pattern, j + 1) end return function() index = index + 1 return returnTable[index] end end for v in SGMatch(str, "%a+") do print(v) end ``` --- ###长串和短串 Lua将长度小于40字节的字符串视为短字符串,短字符串会用哈希表(拉链法实现的哈希表)缓存起来,当Lua声明一个短字符串时,如果缓存中已经存在相同的串则会重复利用,这表示相同内容的短串在一个Lua虚拟机中只会存在一份 --- - Lua的字符串分为`短字符串`和`长字符串`。 - 短字符串:长度小于等于`40`为短字符串。`相同字符的短字符串是共用同一个的`。用hash表使用拉链法缓存起来的,5.3使用版本的hash算法根其他版不一样,要慢一点 - 长字符串:长度大于40为长字符串。`相同的两个长字符串是两个独立的字符串` --- ####设计原因 --- - 复用度:短串复用度会比长串要高 - 哈希效率:由于长串的字符串比较多,如果要把组成它的字符序列进行哈希,耗时会比短串长 [Lua设计与实现--字符串篇](https://zhuanlan.zhihu.com/p/61441722) [深入Lua:字符串管理](https://zhuanlan.zhihu.com/p/97917024) --- ##表 --- - `a.x`代表的是`a["x"]` - `a[x]`则是指由`变量x对应的值`索引的表 --- ```lua local sunday = "monday" local monday = "sunday" local t = { sunday = "monday", [sunday] = monday, } --sunday monday sunday print(t[sunday], t.sunday, t[t.sunday]) ``` --- ###pairs和ipairs --- - `pairs`:遍历的顺序是`随机的`,但是一定会遍历整个表 - `ipairs`:从1开始遍历,如果发现返回值为nil,直接跳出 ```lua local tabFiles = { [3] = "test3", [6] = "test3", [4] = "test4", } --0 print(#tabFiles) --没有打印东西 for k, v in ipairs(tabFiles) do print(k, v) end local tbl = { "alpha", "beta", [3] = "uno", ["two"] = "dos" } --3 print(#tbl) for k, v in ipairs(tbl) do --1 alpha --2 beta --3 uno print(k, v) end --数值型for循环 for i = 1, #tbl do print(tbl[i]) end ``` --- ###table的长度 - `#`:获取的table长度,可能不准确,原因跟ipairs类似 --- ###Lua语言中模拟安全访问操作符 ```lua local temp = {} local zip = (((company or temp).director or temp).address or temp).zipcode --nil print(zip) ``` --- ###table库方法 --- ```lua local t = { 10, 20, 30 } --向序列的指定位置插入一个元素,其他元素依次后移 --{14, 10, 20, 30} table.insert(t, 1, 14) --不带参数:会在序列最后插入指定的元素,并且不会移动任何元素 --{14, 10, 20, 30,40} table.insert(t, 40) --删除并返回指定序列位置的元素, --然后将其后的元素向前移动填充删除元素后的空洞。 --如果调用函数时不指定位置,该函数会删除序列的最后一个元素 --{10, 20, 30,40} table.remove(t, 1) --{10, 20, 30} table.remove(t) --返回表中的特定项连接后的数据,要求所连接的数据必须为数字或者字符串 --10_20_30 print(table.concat(t, "_")) local tbl = { "a", "b", "c" } local newtbl = { 1, 2, 3, 5 } --原型:table.move(a1,f,e,t[,a2]) --函数作用: 把表a1中从下标f到e的value移动到表a2中,位置为a2下标从t开始 --函数参数: 表a1,a1下标开始位置f,a1下标结束位置e,t选择移动到的开始位置(如果没有a2,默认a1的下标) table.move(tbl, 2, 3, 2, newtbl) --1_b_c_5 print(table.concat(newtbl, "_")) table.move(tbl, 2, 3, 3) --a_b_b_c print(table.concat(tbl, "_")) table.move(tbl, 1, #tbl, 2) --a_a_b_b_c print(table.concat(tbl, "_")) ``` --- ###拼接字符串 --- - 使用`table.concat`或者`..` - `..`每次拼接都会产生一个新的字符串 - `table.concat`将table中的元素转换成字符串,再用`分隔符`连接起来。 - `table.concat`没有频繁申请内存,只有当写满一个`8192`的BUFF时,才会生成一个`TString`,最后生成多个`TString`时,会有一次内存申请并合并。在大规模字符串合并时,应尽量选择这种方式 --- ###table是否为nil或者空表 --- ```lua --next查找下一个值,默认从第一个值开始 function IsTableEmpty(t) return t == nil or next(t) == nil end --false print(IsTableEmpty(tbl)) ``` --- ###table的排序 ```lua --默认的情形之下,如果表内既有string,number类型, --则会因为两个类型直接compare而出错,所以需要自己写func来转换一下。 table.sort(tbl, function(a, b) return tostring(a) > tostring(b) end) ``` ##函数 --- - 函数只有`一个参数`且该参数是`字符串常量`或`表构造器`时,括号是可选的`print "Hello wolrd"` 等价于`print("Hello wolrd")` - 通过`抛弃多余参数`和将`不足的参数设为nil`的方式调整参数个数 - 允许一个函数返回多个结果 - 可变长参数函数 ```lua function add(...) local sum = 0 --able.pack,保存所有参数,将其放在一个表中返回, --但是这个表还有一个保存了参数个数的额外字段"n" local pack = table.pack(...) for _, v in ipairs(pack) do sum = sum + v end return sum end print(add(1, 2, 3, 4)) function nonil(...) local arg = table.pack(...) for i = 1, arg.n do if arg[i] == nil then return false end end return true end --false print(nonil(1, 2, nil, 3)) --true print(nonil(1, 2, 3)) ``` - 使用函数select 遍历可变长参数 - select 总是具有一个`固定`的参数`selector` , 以及`数量可变的参数` - 如果selector 是数值`n`,返回`第n个参数后的所有参数` - 如果selector为`#`,返回额外参数的总数 ```lua --a b c print(select(1, 'a', 'b', 'c')) --b c print(select(2, 'a', 'b', 'c')) --c print(select(3, 'a', 'b', 'c')) --3 print(select('#', 'a', 'b', 'c')) function add(...) local sum = 0 for i = 1, select('#', ...) do sum = sum + select(i, ...) end return sum end --0 print(add()) --6 print(add(1, 2, 3)) ``` - `table.pack`:参数列表转换成table - `table.unpack`:将table转换成参数列表 ```lua --1 2 3 print(table.unpack({ 1, 2, 3 })) --显式地限制返回元素的范围 --2 3 print(table.unpack({ 1, 2, 3 }, 2, 3)) local f = string.find local t = { "Hello world", 'll', } --3 4 print(f(table.unpack(t))) --lua端实现的unpack function unpack(t, i, n) i = i or 1 n = n or #t if i <= n then return t[i], unpack(t, i + 1, n) end end --3 4 print(f(unpack(t))) ``` - 尾调用:进行尾调用时不使用任何额外的栈空间,形如 `return fun(args)`的调用才是尾调用 - 注意在使用长度操作符`#`对数组其长度时,数组不应该包含`nil`值,否则很容易出错 ```lua local t = { '5', nil, '6' } --3 print(#t) print(#{ 1, nil }) --1 print(#{ 1, nil, 1 }) --3 print(#{ 1, nil, 1, ['hello'] = '1', nil, 1 }) --5 tb1 = {1, 2, 3, 4, 5} tb1[7] = 7 print("tb1 length: "..#tb1) -- tb1 length: 7 tb2 = {1, 2, 3, 4, 5} tb2[8] = 8 print("tb2 length: "..#tb2) -- tb2 length: 8 tb3 = {1, 2, 3, 4, 5} tb3[8] = 8 tb3[9] = 9 print("tb3 length: "..#tb3) -- tb3 length: 9 tb4 = {1, 2, 3, 4, 5} tb4[2] = nil tb4[3] = nil -- tb4 length: 5 print("tb4 length: "..#tb4) tb4[8]=1 -- tb4 length: 1 print("tb4 length: "..#tb4) ``` --- ###table实现分析 --- - 在table的设计上,采用了`array数组`和`hashtable`(哈希表)两种数据的结合 - table会将部分整形key作为下标放在数组中,其余的整形key和其他类型的key都放在hash表中 --- ```c typedef union TKey { struct { TValuefields; int next; /* 用于标记链表下一个节点 */ } nk; TValue tvk; } TKey; typedef struct Node { TValue i_val; TKey i_key; } Node; typedef struct Table { CommonHeader; lu_byte flags; /* 1<<p means tagmethod(p) is not present */ lu_byte lsizenode; /* log2 of size of 'node' array */ unsigned int sizearray; /* size of 'array' array */ TValue *array; /* array part */ Node *node; Node *lastfree; /* any free position is before this position */ struct Table *metatable; GCObject *gclist; } Table; ``` --- - `flags` : 元方法的标记,用于查询table是否包含某个类别的元方法 - `lsizenode` : (`1<<lsizenode`)表示table的hash部分大小 - `sizearray` : table的数组部分大小 - `array` : table的array数组首节点 - `node` :table的hash表首节点 - `lastfree` : 表示table的hash表空闲节点的游标 - `metatable` : 元表 - `gclist` : table gc相关的参数 --- ####table hash表冲突解决 --- - **开放定址法**:就是一旦发生冲突,通过某种探测技术,去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的freepos。 - **拉链法**:这种方法的思路是将产生冲突的元素建立一个`单链表`,并将`头指针地址`存储至`Hash 表`对应`桶`的位置。这样定位到`Hash表桶`的位置后可通过`遍历单链表`的形式来查找元素 - 开放定址法相比链地址法节省更多的内存,但在插入和查找的时候拥有更高的复杂度 - table中的hash表的实现结合了以上两种方法的一些特性,通过`lastfree`指针找到下一个空的位置,采用拉链法的形式处理冲突,但是链表中的额外的节点是hash表中的node节点,并不需要额外开辟链表节点 --- ####插入新节点流程 --- - 首先检查key值是否合法,若是nil,则直接报错返回 - 获取key对应的`MainPosition`,其中`MainPosition`等于`hash(key)%table_size`,所谓的mainposition是指作为数组访问时的位置索引 - 确定`mainPosition`是否被占用,如果`mainPosition`节点等于dummyNode或者对应`mainPosition`的节点`value`不为null,则表明该`MainPosition`处于占用状态 - 发现`mainPosition`这个索引已经有其他node占用(标记为colliderNode),则需要通过`freePos`游标开始向前查找 - 如果`freePos`没有找到空的Node,则就需要调用`rehash`来扩容,再重新走一次插入流程 - 反之,确定colliderNode节点的MainPosition是否与待插入节点的`mainPosition`一致 - 如果相同直接把待插入节点插入到freePos找到的空Node中 - 如果不同,说明`该节点是被“挤”到该位置来的`,那么把ColliderNode节点挪到`freepos`找到的空node中去,然后让待插入节点入住colliderNode节点原先的坑位 --- 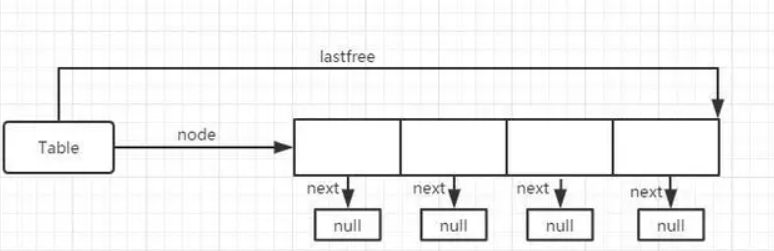 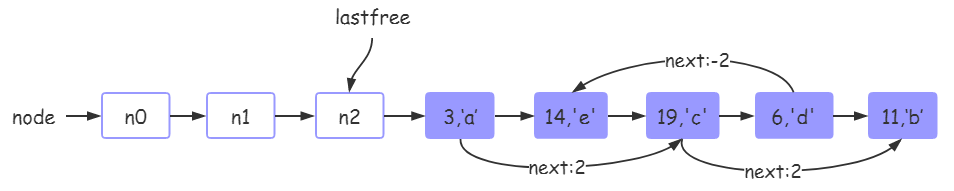 `Rehash`并不一定代表hash表的扩容,而是根据table里面的key的个数和类型,重新更合适的分配array的大小和hash表的大小,可能会扩容、可能不变、也有可能缩小 --- ```c TValue *luaH_newkey (lua_State *L, Table *t, const TValue *key) { Node *mp; TValue aux; if (ttisnil(key)) luaG_runerror(L, "table index is nil"); else if (ttisfloat(key)) { lua_Integer k; if (luaV_tointeger(key, &k, 0)) { /* does index fit in an integer? */ setivalue(&aux, k); key = &aux; /* insert it as an integer */ } else if (luai_numisnan(fltvalue(key))) luaG_runerror(L, "table index is NaN"); } mp = mainposition(t, key); if (!ttisnil(gval(mp)) || isdummy(t)) { /* main position is taken? */ Node *othern; Node *f = getfreepos(t); /* get a free place */ if (f == NULL) { /* cannot find a free place? */ rehash(L, t, key); /* grow table */ /* whatever called 'newkey' takes care of TM cache */ return luaH_set(L, t, key); /* insert key into grown table */ } lua_assert(!isdummy(t)); othern = mainposition(t, gkey(mp)); if (othern != mp) { /* is colliding node out of its main position? */ /* yes; move colliding node into free position */ while (othern + gnext(othern) != mp) /* find previous */ othern += gnext(othern); gnext(othern) = cast_int(f - othern); /* rechain to point to 'f' */ *f = *mp; /* copy colliding node into free pos. (mp->next also goes) */ if (gnext(mp) != 0) { gnext(f) += cast_int(mp - f); /* correct 'next' */ gnext(mp) = 0; /* now 'mp' is free */ } setnilvalue(gval(mp)); } else { /* colliding node is in its own main position */ /* new node will go into free position */ if (gnext(mp) != 0) gnext(f) = cast_int((mp + gnext(mp)) - f); /* chain new position */ else lua_assert(gnext(f) == 0); gnext(mp) = cast_int(f - mp); mp = f; } } setnodekey(L, &mp->i_key, key); luaC_barrierback(L, t, key); lua_assert(ttisnil(gval(mp))); return gval(mp); } ``` 从上面代码可以看出,插入一个节点是先直接插到`hashtable`上的,`array`上都都没有值插入,其实`array`上的值是在rehash的时候会将hashtable中的节点移动过去 --- ####`#table`取长度问题 - `luaH_getn`就是用来求table的长度值的函数 --- ```C int luaH_getn (Table *t) { unsigned int j = t->sizearray; if (j > 0 && ttisnil(&t->array[j - 1])) { /* there is a boundary in the array part: (binary) search for it */ unsigned int i = 0; while (j - i > 1) { unsigned int m = (i+j)/2; if (ttisnil(&t->array[m - 1])) j = m; else i = m; } return i; } /* else must find a boundary in hash part */ else if (isdummy(t)) /* hash part is empty? */ return j; /* that is easy... */ else return unbound_search(t, j); } static int unbound_search (Table *t, unsigned int j) { unsigned int i = j; /* i is zero or a present index */ j++; /* find 'i' and 'j' such that i is present and j is not */ while (!ttisnil(luaH_getint(t, j))) { i = j; if (j > cast(unsigned int, MAX_INT)/2) { /* overflow? */ /* table was built with bad purposes: resort to linear search */ i = 1; while (!ttisnil(luaH_getint(t, i))) i++; return i - 1; } j *= 2; } /* now do a binary search between them */ while (j - i > 1) { unsigned int m = (i+j)/2; if (ttisnil(luaH_getint(t, m))) j = m; else i = m; } return i; } ``` - lua源码并没有进行`遍历查找`,而是通过`二分查找` - 先对数组查找,如果table`数组`部分的`最后一个元素为nil`,那么将在`数组部分进行二分查找` - 如果table数组部分的`最后一个元素不为nil`,那么将在`hash部分进行二分查找` - table中要想`删除一个元素等同于向对应key赋值为nil`,等待垃圾回收。但是删除table一个元素时候,并不会触发表重构行为,即`不会触发rehash操作` - 如果数组中的某个key被赋值为nil,同时最后一个元素不为nil,此时这个数组中的nil就被忽略,直接针对hash部分二分查找,导致找不对 --- ###泛型for的语法 - 泛型for保存了三个值:`一个迭代函数`、`一个不可变状态`、`一个控制变量` ```lua for var-list in exp-list do body end ``` - `var-list`是由一个或多个`变量名`组成的`列表`,用`逗号`分隔 - `exp-list`是一个或多个表达式组成的列表,用`逗号分隔` - 变量列表中的`第一个`(或唯一的)变量称为`控制变量` - 控制变量在循环过程中永远不为nil, 因为当控制变量为nil 时,循环就 - 泛型for就等价于: ```lua for var_1,...,var_n in explist do block end -- 等价于 do local _f, _s, _var =exlist -- 表达式返回 迭代器,不可变状态,控制变量初始值 while true do local var_1,..,var_n = _f(_s,_var) -- 把不可变状态、控制变量初始值作为迭代器的参数,迭代器返回n个值 _var = var_1 if _var == nil then break end -- 迭代器返回的第一个值为nil时,结束循环 end end ``` --- ```lua function values(l) local i = 0 return function() i = i + 1 return l[i] end end local ll = { 10, 20, 30 } local value = values(ll) while true do local v = value() if v then print(v) else break end end for k in values(ll) do print(k) end ``` --- ####无状态迭代器 --- - 是一种自身不保存任何状态的迭代器,可以在多个循环中使用同一个无状态迭代器,避免创建新闭包的开销 - 无状态迭代器,通过返回三个值(`迭代函数、不可变状态、控制变量`),再通过for循环 迭代器,从而完成循环 ```lua local iter = function(t, i) i = i + 1 local v = t[i] if v then return i, v end end --定义的ipairs 函数中会 返回 三个值,其中 分别是 --迭代函数 iter、不可变状态表t 和 控制变量的初始值0 local ipairs = function(t) return iter, t, 0 end --for 循环 ipairs(t) 返回的值符合泛型for执行需要的值,成功完成迭代器的循环 --与 非无状态迭代器相比, 无状态迭代器(例 ipairs)每次for循环时, --都是调用同一迭代函数 iter(),因为没有创建闭包,所以开销小 for k, v in ipairs({ 10, 2, 3 }) do print(k, v) end --调用next(t, nil)时,返回表中的第一个键值对。当所有元素被遍历完,函数next返回nil local pairs = function(t) return next, t, nil end for k, v in pairs({ ["hello"] = 1, ["world"] = 2 }) do print(k, v) end local sort = function(t, i) local a = {} i = i + 1 for k, _ in pairs(t) do a[#a + 1] = k end table.sort(a) if a[i] then --控制变量 return i, a[i], t[a[i]] end end local sortTable = function(t) return sort, t, 0 end for _, k, v in sortTable({ ["luaH_set"] = 10, ["luaH_get"] = 24, ["luaH_present"] = 48, }) do print(k, v) end local fromToIter = function(t, i) if i <= t[1] then --第一个表示变量 --第二个表示返回值 return i + t[2], i end end local fromTo = function(n, m, step) return fromToIter, { m, step }, n end --数值型for应该是指 for i = n,m,1 do something end ,由 n到m 步长为1 for _, v in fromTo(10, 20, 5) do print(v) end ``` --- ##元表 --- - 元表是一类特殊的表,能修改一个值在面对一个未知操作时的行为 - Lua语言中的每一个值都可以有元表 - 在Lua语言中,只能为表设置元表;如果要给其他类型的值设置元表,则必须通过C代码或调试库完成 - 字符串标准库为所有的字符串都设置了同一个元表,而其他类型默认情况下没有元表 --- ```lua local t = {} local m = {} setmetatable(m, t) --table: 0x7fb9e540dca0 table: 0x7fb9e540dca0 print(getmetatable(m), t) --table: 0x7fa5d4408680 table: 0x7fa5d4408680 print(getmetatable("hello"), getmetatable("world")) --nil nil print(getmetatable(10), getmetatable(1)) ``` --- ###元方法 --- <table><tbody> <tr><td><p></p><p>元方法</p></td><td><p>含义</p></td></tr> <tr><td><p>__add</p></td><td><p>加法</p></td></tr><tr><td><p>__mul</p></td><td><p>乘法</p></td></tr><tr><td><p>__sub</p></td><td><p>减法</p></td></tr><tr><td><p>__div</p></td><td><p>除法</p></td></tr><tr><td><p>__idiv</p></td><td><p>floor 除法</p></td></tr> <tr><td><p>__unm</p></td><td><p>负数</p></td></tr><tr><td><p>__mod</p></td><td><p>取模</p></td></tr><tr><td><p>__pow</p></td><td><p>幂运算</p></td></tr><tr><td><p>__band</p></td><td><p>按位与</p></td></tr> <tr><td><p>__bor</p></td><td><p>按位或</p></td></tr> <tr><td><p>__bxor</p></td><td><p>按位异或</p></td></tr> <tr><td><p>__bnot</p></td><td><p>按位取反</p></td></tr> <tr><td><p>__shl</p></td><td><p>向左移位</p></td></tr> <tr><td><p>__shr</p></td><td><p>向右移位</p></td></tr> <tr><td><p>__eq</p></td><td><p>等于</p></td></tr> <tr><td><p>__lt</p></td><td><p>小于</p></td></tr> <tr><td><p>__le</p></td><td><p>小于等于</p></td></tr> <tr><td><p>__tostring</p></td><td><p>tostring 的返回值</p></td></tr> <tr><td><p>__len</p></td><td><p>实现了长度操作符</p></td></tr> <tr><td><p>__index</p></td><td><p>表的查询</p></td></tr> <tr><td><p>__newindex</p></td><td><p>表的更新</p></td></tr> <tr><td><p>__pairs</p></td><td><p>遍历原来的表一样遍历代理</p></td></tr> <tr><td><p>__call</p></td><td><p>表可以通过变量名当作一个函数调用__call方法</p></td></tr> <tr><td><p>__gc</p></td><td><p>table被gc时回调</p></td></tr> </tbody></table> --- ```lua local Set = {} local DefaultMetable = {} function Set.New(l) local set = {} setmetatable(set, DefaultMetable) for _, v in pairs(l) do set[v] = true end return set end function Set.Union(a, b) local res = Set.New {} for k in pairs(a) do res[k] = true end for k in pairs(b) do res[k] = true end return res end function Set.ToString(set) local l = {} for e in pairs(set) do l[#l + 1] = tostring(e) end return "{" .. table.concat(l, ", ") .. "}" end local s1 = Set.New { 10, 20, 30, 50 } local s2 = Set.New { 30, 1 } --table: 0x7f9e61c0e6d0 table: 0x7f9e61c0e6d0 table: 0x7f9e61c0e6d0 print(getmetatable(s1), getmetatable(s2), DefaultMetable) DefaultMetable.__add = Set.Union local s3 = s1 + s2 --{1, 30, 10, 20, 50} print(Set.ToString(s3)) DefaultMetable.__tostring = Set.ToString --{1, 30, 10, 20, 50} print(s3) DefaultMetable.__gc = function(t) print("回收:", t) end local key = {} local defaultMetable = { __index = function(t, k) return t[key] end } local SetDefault = function(t, d) t[key] = d setmetatable(t, defaultMetable) end local tab = { x = 10, y = 30 } SetDefault(tab, 100) --100 print(tab.z) function Track(origin) local proxy = {} local m = { __index = function(t, k) print("*access to element " .. tostring(k)) return origin[k] end, __newindex = function(t, k, v) print("*update of element " .. tostring(k) .. " to" .. tostring(v)) origin[k] = v end, __len = function() return #origin end } setmetatable(proxy, m) return proxy end t = {} t = Track(t) --*update of element 2 tohello t[2] = "hello" --*access to element 2 print(t[2]) t = Track({ 10, 20 }) print(#t) --只读表 function ReadOnly(t) local proxy = {} local mt = { __index = function(_, k) return t[k] end, __newindex = function() error("attempt to update a read-only table", 2) end } setmetatable(proxy, mt) return proxy end local days = ReadOnly { "Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday" } print(days[1]) --days[1] = "M" ``` --- ##协程 --- **线程与协同程序的主要区别:** - 一个具有多个线程的程序可以同时运行几个线程 - 一个具有多个协同程序的程序在任意时刻只能运行一个协同程序,并且正在运行的协同程序只会在其显式地要求挂起时,它的执行才会暂停 --- **协程状态** - 挂起(suspended) - 运行(running) - 死亡(dead) - 正常(normal) --- ```lua local co = coroutine.create(function() print("hello world") end) --suspended print(coroutine.status(co)) coroutine.resume(co) --dead print(coroutine.status(co)) local co = coroutine.create(function() print("hello world") end) --suspended print(coroutine.status(co)) coroutine.resume(co) --dead print(coroutine.status(co)) function foo(a) print("foo", a) return coroutine.yield(2 * a) end local co = coroutine.create(function(a, b) print("co-body", a, b) local r = foo(a) print("co-body r:", r) local x, y = coroutine.yield(a + b, a - b) print("co-body x,y", x, y) return b, "end" end) --co-body 10 1 --foo 10 --main==== true 20 ----------- --co-body r: r --main==== true 11 9 ----------- --co-body x,y X Y --main==== true 1 end --------- --coroutine.resume 的参数,作为传参传入 --coroutine.yield的参数,作为返回值,通过coroutine.resume返回 print("main====", coroutine.resume(co, 10, 1)) print("---------") print("main====", coroutine.resume(co, 'r')) print("---------") print("main====", coroutine.resume(co, "X", "Y")) print("-------") function receiver(prod) local _, v = coroutine.resume(prod) return v end function send(x) coroutine.yield(x) end function product() return coroutine.create(function() while true do local x = io.read() send(x) end end) end function filter(prod) return coroutine.create(function() for line = 1, math.huge do local x = receiver(prod) x = string.format("%5d %s", line, x) send(x) end end) end function consume(prod) while true do local x = receiver(prod) io.write(x, "\n") end end consume(filter(product())) ``` --- ###面向对象 - 冒号操作符:在一个方法调用中`增加一个额外的实`参,或在方法定义中`增加一个额外的隐藏形参` - self作为函数的参数,调用时指定操作的对象 --- ###lua加密策略 - 类似cocos的加密方式,对文件打上加密标记头,然后文件内容呢,加密后存放。需要修改lua加载文件的部分代码。密钥是写死在代码里,所以通过反编译代码很容易获取到。blowfish - luac编译后使用,luac编译后的代码,采用工具能够恢复一部分,可读性不强,可以作为一般应用的加密方式 - 将加密解密的函数,由服务端传入。客户端执行这个函数加载相应模块。需要封装读取文件接口给LUA用。 这种方式,非常隐蔽 - 修改lua虚拟机中,指令的编号,然后使用luac进行编译。这样的方式luac编译后的字节码中,指令编号与其它的不同,是非常好的机密方式 --- lua c api 0904学习