C# 知识树整理——内存探索
本文由 简悦 SimpRead 转码, 原文地址 www.cnblogs.com
C# 内存管理
对象的基本内存大小
基本类型的内存占用
数据类型 32 位 64 位 取值范围(32 位) char -(没测试) 2 byte 1 1 0~255 sbyte 1 1 –32,768~32,767 ushort 2 2 0~65,535 int 4 4 -2,147,483,648~2,147,483,647 uint 4 4 0~4,294,967,295 ulong 4 8 0~4,294,967,295 float 4 4 3.4E +/- 38 (7 digits) double 8 8 1.7E +/- 308 (15 digits) 求 struct 和 class 的大小
public struct MyStructNull{}public struct MyStruct{private int a;}public class MyClassNull{}public class MyClassint{private int a;}public class MyClassLong{private long a;}public class MyClassByte{private byte a1;private byte a2;private byte a3;}static class Program{private static void CaculateMemory<T>(Func<T> action){GC.Collect(0);long start = GC.GetTotalMemory(true);var a = action();GC.Collect(0);long end = GC.GetTotalMemory(true);Console.WriteLine(end - start);}static void Main(){Console.WriteLine(Marshal.SizeOf(new MyStructNull()));//1Console.WriteLine(Marshal.SizeOf(new MyStruct()));//4CaculateMemory((() =>{return new MyClassNull();}));//12CaculateMemory((() =>{return new MyClassint();}));//12CaculateMemory((() =>{return new MyClassLong();}));//16CaculateMemory((() =>{return new MyClassByte();}));//12}}
Struct 验证结果为 1,空的 struct 是 1,理论上是 0,编译器实现为 1,如果里面有了数据就是数据实际大小,不会多 1。
Class 就有意思了,空类为 12,加了个 int 还是 12,这让我十分困惑,但是有了 Struct 的经验,我又做了 2 个测试,当内部有个 long 的时候是 16,多了 4,也符合 long 和 int 的差值,那我加个 3byte 的话,就应该是 11,和 int 差 1(也可以加 1 个但是为了引出我接下来的测试就用 3 个 byte),我试着打印了个 byteclass 的大小,结果也为 12,再根据操作系统的内存对其的理论,我有个猜想,当然纯粹是笔者自己的设想没有验证过,当 class 为空类时,实际大小为 9,内存对其后变成 12,当 class 有值的时候,class 大小为 8,至于为什么为 8?其实真正的情况是一个引用类型创建的时候会附带一个类型指针,和一个同步块索引的指针,这部分是在 CLR 中实现的,在 32 位系统下一个指针 4 字节,所以大小是 8,内存对其按 4 字节对齐
那我又有一个想法,C++ 中的 Struct 属性排列方式会影响 struct 的内存大小,在 C + 中是否还存在?
public struct MyStructA{private int a;private long b;private char c;}public struct MyStructB{private int a;private char c;private long b;}static class Program{static void Main(){Console.WriteLine(Marshal.SizeOf(new MyStructA()));//24Console.WriteLine(Marshal.SizeOf(new MyStructB()));//16}}
事实证明属性的排布对于 Struct 的影响还是存在的,具体关于 struct 内存的详细解析可以看(C++ 的内存管理),这里就不复述了,这里面写得挺详细的
C# 的内存分配探索
C++ 中默认的 operator new 底层调用的是 malloc,在分配内存时会带上上下 cookie 用于内存回收和内存碎片合并,现在到了 C# 中,因为 C# 有独有的垃圾回收机制,那我就比较好奇 C# 中对于对象内存的排列是怎么样的,还有没有上下 cookie 存在呢?所以我进行了下面的测试
public class MyClassInt{private long a;}public class MyClassLong{private int a;}static class Program{for (int i = 0; i < 3; i++){printMemory(new MyClassInt());}Console.WriteLine();for (int i = 0; i < 3; i++){printMemory(new MyClassLong());}public static void printMemory(object o) // 获取引用类型的内存地址方法{GCHandle h = GCHandle.Alloc(o, GCHandleType.WeakTrackResurrection);IntPtr addr = GCHandle.ToIntPtr(h);Console.WriteLine("0x" + addr.ToString("X"));}/*输出0xF010F80xF010F40xF010F00xF010EC0xF010E80xF010E4*/}
起初对于 MyClassInt 的输出我很惊讶,因为 int 的 size 刚好是 4,我本来认为是 C# 对于内存分配器进行了特殊的管理,比如类似 gunc 的 pool_alloc 这样的设计,去掉了 cookie,使得对象的大小就是纯粹的 size 大小间隔,结果想想不太对劲,还是不能靠猜,在试试其他的,一试就试出来了。。。换成了 long 以后按推理方式来说应该是间隔 8,才是纯粹的 size 大小,结果一看并不是,还是 4…fuck,所以其实这个 C# 中通过 new 内存并没有带上对象的地址,所以可以看出来打印的应该是引用的地址段,每个地址段 4 字节,没有 cookie,至于指针指向的地方有没有 cookie?不得而知,不过这里可以看出这这这样的设计和 C# 的垃圾回收器有很大关系。且还有个好玩的点,不同类型的内存地址也是连续的,用的是一同一个地址段。接下来再进行一个测试:
for (int i = 0; i < 100000; i++){printMemory(new MyClassInt());}/*其他代码不变0x12F10F80x12F10F40x12F10F0...0x12F10000x12F14FC0x12F14F80x12F14F4...0x12F14000x12F15FC0x12F15F8...0x12FFF080x12FFF040x12FFF000x31E10FC0x31E10F80x31E10F4...0x31EFF000x31F10FC...0x31FFF000x57E10FC*/
这里我想知道一次分配器分配的大小是多少,不够的时候是什么时候要新的内存块?所以我进行了这个测试,测试下来结果我总结了一下:
首先先是开始的时候总是以 XXXXF8 开始的,十进制是 248
然后新分配的内存会递减这个内存段,直到变成 00
变成 00 后会去要当前这个地址段前三位(F10)后最近的可用的地址段,比如当前是 F10 就去看看 F11 可用吗,不行就找 F12,依次,比如例中找到了 F10 用完找到了 F14,F14 用完找 F15 依次内推
找到后分配的大小是从 FC 开始,252,对比于 256 差了 4,很可能用了这个 4 记录了这个内存块用于 GC 的信息,比如这个内存块的引用计数。
然后当倒数第五到第三这两位也用完后(变为 FFF),那就会分配新的地址段,也是递增搜寻。所以新地址是 31E,默认从 E10FC 开始(921836),结束是 FFF00(1048320),可用 126484,每个对象为 4 的话就是 31621 个对对象
继续探索,如果想要继续往下的话就得去深挖看看 GCHandle.Alloc 的分配
如果深入研究
GCHandle.Alloc,您会看到它调用了一个本地方法InternalAlloc:[System.Security.SecurityCritical] // auto-generated[MethodImplAttribute(MethodImplOptions.InternalCall)][ResourceExposure(ResourceScope.None)]internal static extern IntPtr InternalAlloc(Object value, GCHandleType type);
其中 InternalAlloc 是 CLR 公共库的代码,其中就有这里核心的一个部分,CLR 垃圾回收器
其中 InternalAlloc 的核心就是这一句:
hnd = GetAppDomain()->CreateTypedHandle(objRef, type);依次调用
ObjectHandle::CreateTypedHandle->HandleTable::HndCreateHandle->HandleTableCache->TableAllocSingleHandleFromCache,如果缓存堆中存在则返回,不存在则分配,这里方法调用的时候我已经 new 了这个对象了,所以对象是存在的,存在会返回这个对象的 IntPtr。在托管堆中发生的唯一分配是IntPtr,它保存指向表中地址的指针。所以我疯狂 print 的都是这个指针的地址,所以我探究的也是这个 intPtr 的分配策略,当我明白这一点的时候,我就发现,诶嘿,我又可以水一篇 C#GC 探索的文章了,所以我跟到了 CLR 的库,开始研究 CLR 的 GC 原理,看看没有官方的解释和源码来论证我上述的猜想,所以… 下期再见~
GC
什么是 GC
- GC 如其名,就是垃圾收集,当然这里仅就内存而言。Garbage Collector(垃圾收集器,在不至于混淆的情况下也成为 GC)以应用程序的 root 为基础,遍历应用程序在 Heap 上动态分配的所有对象,通过识别它们是否被引用来确定哪些对象是已经死亡的、哪些仍需要被使用。已经不再被应用程序的 root 或者别的对象所引用的对象就是已经死亡的对象,即所谓的垃圾,需要被回收。这就是 GC 工作的原理。为了实现这个原理,GC 有多种算法。比较常见的算法有:
- 引用计数法 (Reference Counting)
- 标记 - 清除 (Mark-Sweep)
- 标记 - 压缩 (Mark-Compact)
- 复制收集法 (Copy Collection)
- …
- 目前主流的虚拟系统. NET CLR,Java VM 和 Rotor 都是采用的标记 - 清除 + 标记 - 压缩 + 复制收集法算法。
- GC 如其名,就是垃圾收集,当然这里仅就内存而言。Garbage Collector(垃圾收集器,在不至于混淆的情况下也成为 GC)以应用程序的 root 为基础,遍历应用程序在 Heap 上动态分配的所有对象,通过识别它们是否被引用来确定哪些对象是已经死亡的、哪些仍需要被使用。已经不再被应用程序的 root 或者别的对象所引用的对象就是已经死亡的对象,即所谓的垃圾,需要被回收。这就是 GC 工作的原理。为了实现这个原理,GC 有多种算法。比较常见的算法有:
CLR 的垃圾回收实现
Mark-Compact 标记压缩算法
阶段 1: Mark-Sweep 标记清除阶段,先假设 heap 中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后 heap 中没有打标记的对象都是可以被回收的
阶段 2: Compact 压缩阶段,对象回收之后 heap 内存空间变得不连续,在 heap 中移动这些对象,使他们重新从 heap 基地址开始连续排列,类似于磁盘空间的碎片整理。
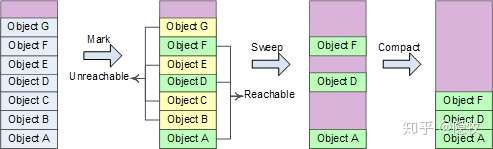
Heap 内存经过回收、压缩之后,可以继续采用前面的 heap 内存分配方法,即仅用一个指针记录 heap 分配的起始地址就可以。主要处理步骤:将线程挂起→确定 roots→创建 reachable objects graph→对象回收→heap 压缩→指针修复。可以这样理解 roots:heap 中对象的引用关系错综复杂(交叉引用、循环引用),形成复杂的 graph,roots 是 CLR 在 heap 之外可以找到的各种入口点。
GC 搜索 roots 的地方包括全局对象、静态变量、局部对象、函数调用参数、当前 CPU 寄存器中的对象指针(还有 finalization(析构) queue)等。主要可以归为 2 种类型:已经初始化了的静态变量、线程仍在使用的对象(stack+CPU register) 。 Reachable(可达) objects:指根据对象引用关系,从 roots 出发可以到达的对象。例如当前执行函数的局部变量对象 A 是一个 root object,他的成员变量引用了对象 B,则 B 是一个 reachable object。从 roots 出发将可达对象全部标记完毕,剩余对象即为不可达对象,可以被回收 。
GC roots 这组引用是 tracing GC 的 起点。要实现语义正确的 tracing GC,就必须要能完整枚举出 所有的 GC roots,否则就可能会漏扫描应该存活的对象,导致 GC 错误回收了这些被漏扫的活对象。
指针修复是因为压缩过程移动了 heap 对象,对象地址发生变化,需要修复所有引用指针,包括 stack、CPU register 中的指针以及 heap 中其他对象的引用指针。Debug 和 release 执行模式之间稍有区别,release 模式下后续代码没有引用的对象是 unreachable 的,而 debug 模式下需要等到当前函数执行完毕,这些对象才会成为 unreachable,目的是为了调试时跟踪局部对象的内容。传给了 COM + 的托管对象也会成为 root,并且具有一个引用计数器以兼容 COM + 的内存管理机制,引用计数器为 0 时,这些对象才可能成为被回收对象。Pinned objects 指分配之后不能移动位置的对象,例如传递给非托管代码的对象(或者使用了 fixed 关键字),GC 在指针修复时无法修改非托管代码中的引用指针,因此将这些对象移动将发生异常。pinned objects 会导致 heap 出现碎片,但大部分情况来说传给非托管代码的对象应当在 GC 时能够被回收掉。
Generational 分代算法
程序可能使用几百 M、几 G 的内存,对这样的内存区域进行 GC 操作成本很高,分代算法具备一定统计学基础,对 GC 的性能改善效果比较明显。将对象按照生命周期分成新的、老的,根据统计分布规律所反映的结果,可以对新、老区域采用不同的回收策略和算法,加强对新区域的回收处理力度,争取在较短时间间隔、较小的内存区域内,以较低成本将执行路径上大量新近抛弃不再使用的局部对象及时回收掉。分代算法的假设前提条件:
1、大量新创建的对象生命周期都比较短,而较老的对象生命周期会更长
2、对部分内存进行回收比基于全部内存的回收操作要快
3、新创建的对象之间关联程度通常较强。heap 分配的对象是连续的,关联度较强有利于提高 CPU cache 的命中率,.NET 将 heap 分成 3 个代龄区域: Gen 0、Gen 1、Gen 2
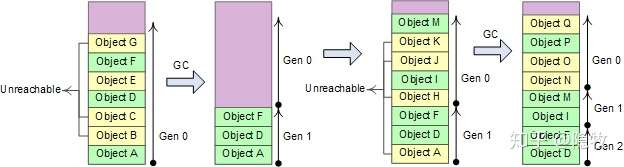
Heap 分为 3 个代龄区域,相应的 GC 有 3 种方式: # Gen 0 collections, # Gen 1 collections, #Gen 2 collections。如果 Gen 0 heap 内存达到阀值,则触发 0 代 GC,0 代 GC 后 Gen 0 中幸存的对象进入 Gen1。如果 Gen 1 的内存达到阀值,则进行 1 代 GC,1 代 GC 将 Gen 0 heap 和 Gen 1 heap 一起进行回收,幸存的对象进入 Gen2。
2 代 GC 将 Gen 0 heap、Gen 1 heap 和 Gen 2 heap 一起回收,Gen 0 和 Gen 1 比较小,这两个代龄加起来总是保持在 16M 左右;Gen2 的大小由应用程序确定,可能达到几 G,因此 0 代和 1 代 GC 的成本非常低,2 代 GC 称为 full GC,通常成本很高。粗略的计算 0 代和 1 代 GC 应当能在几毫秒到几十毫秒之间完成,Gen 2 heap 比较大时,full GC 可能需要花费几秒时间。大致上来讲. NET 应用运行期间,2 代、1 代和 0 代 GC 的频率应当大致为 1:10:100。
Finalization Queue(析构队列)和 Freachable Queue(可达队列)
- 这两个队列和. NET 对象所提供的析构方法有关。这两个队列并不用于存储真正的对象,而是存储一组指向对象的指针。当程序中使用了 new 操作符在 Managed Heap 上分配空间时,GC 会对其进行分析,如果该对象含有析构方法则在析构队列中添加一个指向该对象的指针
- 在 GC 被启动以后,经过 Mark 阶段分辨出哪些是垃圾。再在垃圾中搜索,如果发现垃圾中有被析构队列中的指针所指向的对象,则将这个对象从垃圾中分离出来,并将指向它的指针移动到 Freachable Queue(终结队列)中。这个过程被称为是对象的复生(Resurrection),本来死去的对象就这样被救活了。为什么要救活它呢?因为这个对象的析构方法还没有被执行,所以不能让它死去。Freachable Queue 平时不做什么事,但是一旦里面被添加了指针之后,它就会去触发所指对象的析构方法执行,之后将这个指针从队列中剔除,这是对象就可以安静的死去了。
- .NET Framework 的 System.GC 类提供了控制析构的两个方法,ReRegisterForFinalize 和 SuppressFinalize。前者是请求系统完成对象的 Finalize 方法,后者是请求系统不要完成对象的 Finalize 方法。ReRegisterForFinalize 方法其实就是将指向对象的指针重新添加到 Finalization Queue 中。这就出现了一个很有趣的现象,因为在析构队列中的对象可以复生,如果在对象的 Finalize 方法中调用 ReRegisterForFinalize 方法,这样就形成了一个在堆上永远不会死去的对象,像凤凰涅槃一样每次死的时候都可以复生。
托管资源:
.NET 中的所有类型都是(直接或间接)从 System.Object 类型派生的。
- CTS 中的类型被分成两大类——引用类型(reference type,又叫托管类型 [managed type]),分配在内存堆上;值类型(value type),分配在堆栈上。如图:
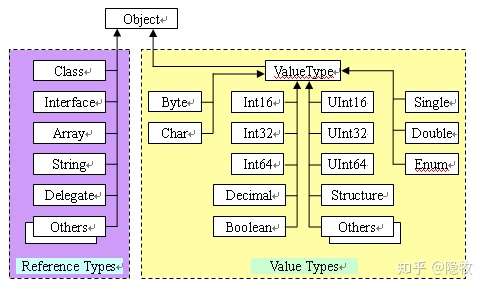
值类型在栈里,先进后出,值类型变量的生命有先后顺序,这个确保了值类型变量在退出作用域以前会释放资源。比引用类型更简单和高效。堆栈是从高地址往低地址分配内存。
引用类型分配在托管堆 (Managed Heap) 上,声明一个变量在栈上保存,当使用 new 创建对象时,会把对象的地址存储在这个变量里。托管堆相反,从低地址往高地址分配内存。
非托管资源:
ApplicationContext, Brush, Component, ComponentDesigner, Container, Context, Cursor, FileStream, Font, Icon, Image, Matrix, Object, OdbcDataReader, OleDBDataReader, Pen, Regex, Socket, StreamWriter, Timer, Tooltip, 文件句柄, GDI 资源, 数据库连接等等资源。可能在使用的时候很多都没有注意到!
.NET 的 GC 机制有这样两个问题:
- GC 并不是能释放所有的资源。它不能自动释放非托管资源。
- GC 并不是实时性的,这将会造成系统性能上的瓶颈和不确定性。
- GC 并不是实时性的,这会造成系统性能上的瓶颈和不确定性。所以有了 IDisposable 接口,IDisposable 接口定义了 Dispose 方法,这个方法用来供程序员显式调用以释放非托管资源。使用 using 语句可以简化资源管理。当你用 Dispose 方法释放未托管对象的时候,应该调用 GC.SuppressFinalize。如果对象正在终结队列 (finalization queue), GC.SuppressFinalize 会阻止 GC 调用 Finalize 方法。因为 Finalize 方法的调用会牺牲部分性能。如果你的 Dispose 方法已经对委托管资源作了清理,就没必要让 GC 再调用对象的 Finalize 方法 (MSDN)
GC 注意事项:
- 只管理内存,非托管资源,如文件句柄,GDI 资源,数据库连接等还需要用户去管理。
- 循环引用,网状结构等的实现会变得简单。GC 的标志 - 压缩算法能有效的检测这些关系,并将不再被引用的网状结构整体删除。
- GC 通过从程序的根对象开始遍历来检测一个对象是否可被其他对象访问,而不是用类似于 COM 中的引用计数方法。
- GC 在一个独立的线程中运行来删除不再被引用的内存。
- GC 每次运行时会压缩托管堆。
- 你必须对非托管资源的释放负责。可以通过在类型中定义 Finalizer 来保证资源得到释放。
- 对象的 Finalizer(析构)被执行的时间是在对象不再被引用后的某个不确定的时间。注意并非和 C++ 中一样在对象超出声明周期时立即执行析构函数
- Finalizer 的使用有性能上的代价。需要 Finalization 的对象不会立即被清除,而需要先执行 Finalizer.Finalizer,不是在 GC 执行的线程被调用。GC 把每一个需要执行 Finalizer 的对象放到一个队列中去,然后启动另一个线程来执行所有这些 Finalizer,而 GC 线程继续去删除其他待回收的对象。在下一个 GC 周期,这些执行完 Finalizer 的对象的内存才会被回收。
- .NET GC 使用 “代”(generations) 的概念来优化性能。代帮助 GC 更迅速的识别那些最可能成为垃圾的对象。在上次执行完垃圾回收后新创建的对象为第 0 代对象。经历了一次 GC 周期的对象为第 1 代对象。经历了两次或更多的 GC 周期的对象为第 2 代对象。代的作用是为了区分局部变量和需要在应用程序生存周期中一直存活的对象。大部分第 0 代对象是局部变量。成员变量和全局变量很快变成第 1 代对象并最终成为第 2 代对象。
- GC 对不同代的对象执行不同的检查策略以优化性能。每个 GC 周期都会检查第 0 代对象。大约 1/10 的 GC 周期检查第 0 代和第 1 代对象。大约 1/100 的 GC 周期检查所有的对象。重新思考 Finalization 的代价:需要 Finalization 的对象可能比不需要 Finalization 在内存中停留额外 9 个 GC 周期。如果此时它还没有被 Finalize,就变成第 2 代对象,从而在内存中停留更长时间。
堆和栈
- 栈区:由编译器自动分配释放 ,存放值类型的对象本身,引用类型的引用地址(指针),静态区对象的引用地址(指针),常量区对象的引用地址(指针)等。其操作方式类似于数据结构中的栈。
- 堆区(托管堆): 用于存放引用类型对象本身。在 c# 中由. net 平台的垃圾回收机制(GC)管理。栈,堆都属于动态存储区,可以实现动态分配。
- 静态区及常量区:用于存放静态类,静态成员(静态变量,静态方法),常量的对象本身。由于存在栈内的引用地址都在程序运行开始最先入栈,因此静态区和常量区内的对象的生命周期会持续到程序运行结束时,届时静态区内和常量区内对象才会被释放和回收(编译器自动释放)。所以应限制使用静态类,静态成员(静态变量,静态方法),常量,否则程序负荷高.
- 代码区:存放函数体内的二进制代码。
参考资料
C# 知识体系构建
C# 程序设计视频教程
C# 笔记
垃圾回收算法详解(引用计数 / 标记 - 清除 / 标记压缩 / 复制算法)
C# 技术漫谈之垃圾回收机制 (GC)
浅析 C# Dictionary 实现原理
C# 装箱和拆箱(Boxing 和 UnBoxing)
EOF