C#知识树整理——C#基础 agile Posted on Jun 18 2023 c# > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.cnblogs.com](https://www.cnblogs.com/moran-amos/p/14366344.html) c# 基础 ----- * **C# 1.0** * 类(Class) * 类可以继承 * 包含属性 * 包含方法 * 可以用来创建对象 * 类的访问权限 * Internal:在打 dll 的时候作用很大,可以控制有些类不然用户访问到 * private:用得不多,一般作为内部类存在 * public:这个不用多说懂的都懂 * 抽象类与接口 * 抽象类中的抽象方法,子类在继承时必须要进行覆写,抽象类不一定有抽象方法,抽象类中可以有非抽象方法 * 接口中的方法都是抽象方法,接口中可以设置变量。接口分为显示实现和隐式实现,详见底下的接口展开。 * 内部类 ``` public class A { private class B{}//内部类 public void NewB() { B b = new B(); } } ``` * 有些类只需要在类内部使用,就可以创建内部类 * partial 关键字 ``` public partial class A { } ``` * 类定义的代码可以拆分到不同的文件当中,只要实现的时候在类前加上 partial 就行 * 泛型类 ``` public partial class<T> A { private T inst; } ``` * 类需要适配不同类型的时候可以用泛型类,比如单例的实现 * 结构(struct) ``` public struct MyStruct { /* 会报错,隐式的无参数的构造函数在结构中无论如何都是存在的,所以程序员不能手动的为结构添加1个无参数的构造函数. public MyStruct() { } //struct没有析构 ~ MyStruct() { Debug.Log("我析构了"); } */ public MyStruct(int a,int b) { this.a = a; this.b = b; } private int a; private int b; // private int a = 1;//设置初始值编译会报错 public static int staticA = 1;//static和const可以 public const int constA = 1;//static和const可以 } //与Class对比 public class MyClass { public MyClass(){} ~MyClass() { Debug.Log("我析构了"); } public MyClass(int a,int b) { this.a = a; this.b = b; } private int a = 1; private int b; public static int staticA = 1; public const int constA = 1; } public class Test:MonoBehaviour { void Start() { MyStruct myStruct = new MyStruct(); MyStruct myStruct1 = new MyStruct(1,2); MyClass myCls = new MyClass(); MyClass myCls1 = new MyClass(1,2); } } ``` * 常见、重要的特性 * 是值类型 * 不能设置为 null * 声明变量时本身就有值了 * 赋值时是深拷贝 * 不能局部赋值 * 其他细节 * 在结构声明中除非声明 static 或 const,否则无法初始化 * 结构不能声明无参构造函数或析构 * 结构在分配时进行复制,将结构分配给新变量时,将复制所有数据,并且对新副本所做的任何修改不会影响原始副本的数据,在处理值类型的集合(如`Dictionary<string,myStruct>`)请注意这点 * 结构是值类型,不同于类,类是引用类型 * 与类不同无需用 new 进行初始化 * 结构可以声明具有参构造 * 一个结构无法继承自另一个结构或者类,也不能成为类的基类。所有结构都直接继承自 ValueType,否则继承自 Object * 结构可以实现接口 * 和类的区别 * 结构不能声明无参构造函数或析构 * 与类不同无需用 new 进行初始化 * 一个结构无法继承自另一个结构或者类,也不能成为类的基类。所有结构都直接继承自 ValueType,否则继承自 Object * 结构是值类型,不同于类,类是引用类型 * 在结构声明中除非声明 static 或 const,否则无法初始化 * 接口(interface) ``` public interface IMyInterface { void Func(); } public class MyHideCls : IMyInterface { public void Func()//隐式实现 { } } public class MyShowCls : IMyInterface { void IMyInterface.Func()//显式实现 { } } void Main() { (new MyHideCls()).Func();//调用隐式实现 // (new MyShowCls()).Func();//调用显示实现会报错 ((IMyInterface)(new MyShowCls())).Func();//必须要当接口对象使用 } ``` * 隐式实现:就基本的方式 * 显式实现:需要当成接口对象用才能使用此方法 * 显示实现的应用场景: * 解决重名方法问题: ``` public interface IDog { void Run(); } public interface IPig { void Run(); } public class MyCls : IDog,IPig { void IDog.Run()//指定实现的是哪个,避免方法重名 { } void IPig.Run() { } } ``` * 降低方法的访问权限 ``` public interface ICmommand { void Run(); } public class Cmommand : ICmommand { void ICmommand.Run() { Debug.Log("Cmommand Run"); } } public class ChildCommand : Cmommand { } public class CmommandHelper { public static void Run(ICmommand cmd) { cmd.Run(); } } void Main() { ChildCommand child = new ChildCommand(); // child.Run();//防止用户误操作直接调用隐式实现 CmommandHelper.Run(child);//托管给专门的执行器去做 } ``` * 细节补充: * 实现接口的任何类或者结构都必须实现其所有成员 * 接口类似于只有抽象成员的抽象基类 * 一个类可以继承一个基类,还可以实现多个接口 * 接口无法直接进行实例化 * 其成员由实现接口的任何类或结构来实现 * 接口可以包含事件、索引器、方法和属性 * 接口不包含方法的实现 * 一个类或者结构可以实现多个接口 * 什么是接口和抽象类 * 接口和抽象类都是 “软件工程产物” * 具体类 -> 抽象类 -> 接口:越来越抽象,内部实现的东西越来越少 * 抽象类是未完全实现逻辑的类(可以有字段和非 public 成员,它们代表了 “具体逻辑”) * 抽象类为复用而生:专门作为基类来使用。也具有解耦功能 * * 解耦的具体内容留待下一节讲接口时讲 * 封装确定的,开放不确定的(开闭原则),推迟到合适的子类中去实观 * 接口是完全未实现逻辑的 “类”(“纯虚类”;只有函数成员;成员全部 public) * 接口为解耦而生:“高内聚,低耦合”,方便单元测试 * 接口是一个 “协约”。早已为工业生产所熟知(有分工必有协作,有协作必有协约) * 它们都不能实例化。只能用来声明变量、引用具体类(concrete class)的实例 * 胖接口及其产生原因 * 观察传给调用者的接口里面有没有一直没有调用的函数成员,如果有,就说明传进来的接口类型太大了。换句话说,这个 “胖” 接口是由两个或两个以上的小接口合并起来的 * 属性器(Property) * Get 和 Set 方法 * 隔离内部变化,凸显封装性 * 委托(Deldgates) * 委托(delegate)是函数指针的 “升级版” * 委托的基本用法: * 模板方法,借用指定的外部方法产生结果(现在一般用接口替代) * 回调方法,调用指定的外部方法。 * 高级使用: * 多播:`action1 += action2;` * 隐式异步调用: `action1.BeginInvoke(null, null);` * 常用委托: * `Action<T>`返回值是 void * `Func<T>`返回值是 T * 使用经验: * 为了防止空指针异常,可以给委托一个初始值 * 委托可以用 Lambert 表达式 * 事件(Event) * 事件模型的五个组成部分 * 事件的拥有者 * 事件的成员(事件本身) * 事件的响应者 * 事件的处理器 * 事件的订阅 * 有了委托为什么还需要事件 * 为了 程序的逻辑更加 “有道理”,谨防借刀杀人 * 事件的本质是委托字段的一个包装器 * 只能在声明类的内部 invoke * 属性器不是 get 和 set 而是 add 和 remove [](https://cdn.nlark.com/yuque/0/2018/png/101969/1539307771348-c4ce0c6b-f8dd-47fa-b205-e4dc36f90cec.png?x-oss-process=image%2Fresize%2Cw_827) [](https://cdn.nlark.com/yuque/0/2018/png/101969/1539308429079-64ac6227-244b-4ffa-8689-52905bdbe170.png?x-oss-process=image%2Fresize%2Cw_827) * 事件与委托的关系 * 事件真的是 “以特殊方式声明的委托字段 / 实例” 吗? * * 不是!只是声明的时候 “看起来像”(对比委托字段与事件的简化声明,field-like) * 事件声明的时候使用了委托类型,简化声明造成事件看上去像一个委托的字段(实例),而 event 关键字则更像是一个修饰符 —— 这就是错觉的来源之一 * 订阅事件的时候 += 操作符后面可以是一个委托实例,这与委托实例的赋值方法语句相同,这也让事件看起来像是一个委托字段 —— 这是错觉的又一来源 * 重申:事件的本质是加装在委托字段上的一个 “蒙版”(mask),是个起掩蔽作用的包装器。这个用于阻挡非法操作的“蒙版” 绝不是委托字段本身 * 为什么要使用委托类型来声明事件? * * 站在 source 的角度来看,是为了表明 source 能对外传递哪些消息 * 站在 subscriber 的角度来看,它是一种约定,是为了约束能够使用什么样签名的方法来处理(响应)事件 * 委托类型的实例将用于存储(引用)事件处理器 * 对比事件与属性 * * 属性不是字段 —— 很多时候属性是字段的包装器,这个包装器用来保护字段不被滥用 * 事件不是委托字段 —— 它是委托字段的包装器,这个包装器用来保护委托字段不被滥用 * **包装器永远都不可能是被包装的东西** * 表达式 * 表达式值 * 数值 * 字符串 * 调用表达式 * 调用方法 * 调用委托 * 查询表达式 * LINQ * lambda 表达式 * 其他概念 * 表达式树 * 表达式主体 * 重要特性 * 运算符优先级 * 语句 * 定义:可以用分号结尾的代码就是语句 * 类型: * 声明表达式 * 表达式语句 * 迭代语句 * 跳转语句 * 异常处理语句 * await 语句 * yield return 语句 * fixed 语句 * lock 语句 * 空语句 * ... * 特性 * 自定义 Attribute * 继承 system.Attribute * 与反射配合使用 * 面向对象 * 核心是对象的建模 * 类能比较容易的进行面向对象的编程,没有类也能做到但是不那么容易 * C、lua 这样的面向过程的语言也都能模拟面向对象 * 面向对象和面向过程不是独立的 * 面向对象更擅长设计 * 面向过程更擅长实现 * 面向对象以对象为基础单位 * 面向过程以函数为基础单位 * **引用类型和值类型** * 用类创建的类型就是引用类型(string,class) * 用结构体或者值类型创建出来的类型就是值类型(bytes,short,int,long,float,double,decimal,char,bool 和 struct) * 值类型直接存储其值,而引用类型存的是其引用(也就类似于指针指向了那个内存地址) * 反射 * 定义: * 提供封装程序集、模块和类型的对象 * 就是对 Type 的 Api 进行一系列的操作 * 给我一个对象,我能在不用 new 操作符也不知道该对象的静态类型的情况下,我能给你创建出一个同类型的对象,还能访问该对象的各个成员 * 当程序处于动态期(dynamic)用户已经用上了,不再是开发时的静态期(static)。动态期用户和程序间的操作是难以预测的,如果你要在开始时将所有情况都预料到,那程序的复杂度难免太高,指不定就是成百上千的 if else,即使你真的这样做了,写出来的程序也非常难维护,可读性很低。很多时候更有可能是我们在编写程序时无法详尽枚举出用户可能进行的操作,这时我们的程序就需要一种**以不变应万变**的能力,反射就是这个窍门。 * 反射毕竟是动态地去内存中获取对象的描述、对象类型的描述,再用这些描述去创建新的对象,整个过程会影响程序性能,所以不要盲目过多地使用反射 * type 的获取 * typeof * object.GetType() * var type = Type.GetType("类的 fullName"); * TypeApi 分类 * 类查询 API * FuName * Name * ... * 检测 API * IsClass * IsAbstract * ... * 类结构查询 API * BaseType 获取父类类型 * GetMembers 获取类成员(方法,属性,字段) * GetFields 获取所有字段 * GetProperties 获取所有属性器 * GetMethod 获取所有方法 * BindingFlags 控制搜索结果 * Assembly 提供的 API * Assembly.LoadFrom(fullPath) * Assembly.GetExecutingAssembly() * Assembly.CreateInstance(typeName) * 控制反转和依赖注入 * 控制反转(依赖反转) * 举一个现实生活的例子: 海尔公司作为一个电器制商需要把自己的商品分销到全国各地,但是发现,不同的分销渠道有不同的玩法,于是派出了各种销售代表玩不同的玩法,随着渠道越来越多,发现,每增加一个渠道就要新增一批人和一个新的流程,严重耦合并依赖各渠道商的玩法。实在受不了了,于是制定业务标准,开发分销信息化系统,只有符合这个标准的渠道商才能成为海尔的分销商。让各个渠道商反过来依赖自己标准。反转了控制,倒置了依赖。 我们把海尔和分销商当作软件对象,分销信息化系统当作 IOC 容器,可以发现,在没有 IOC 容器之前,分销商就像图 1 中的齿轮一样,增加一个齿轮就要增加多种依赖在其他齿轮上,势必导致系统越来越复杂。开发分销系统之后,所有分销商只依赖分销系统,就像图 2 显示那样,可以很方便的增加和删除齿轮上去。 * 依赖注入 * 就是将实例变量传入到一个对象中去 (Dependency injection means giving an object its instance variables)。 * 什么是依赖: ``` public class Human { ... Father father; ... public Human() { father = new Father(); } } ``` 类 Human 中用到一个 Father 对象,我们就说类 Human 对类 Father 有一个依赖。 仔细看这段代码我们会发现存在一些问题: 1、如果现在要改变 father 生成方式,如需要用 new Father(String name) 初始化 father,需要修改 Human 代码; 2、如果想测试不同 Father 对象对 Human 的影响很困难,因为 father 的初始化被写死在了 Human 的构造函数中; 3、如果 new Father() 过程非常缓慢,单测时我们希望用已经初始化好的 father 对象 Mock 掉这个过程也很困难。 * 依赖注入 ``` public class Human { ... Father father; ... public Human(Father father) { this.father = father; } } ``` 上面代码中,我们将 father 对象作为构造函数的一个参数传入。在调用 Human 的构造方法之前外部就已经初始化好了 Father 对象。像这种非自己主动初始化依赖,而通过外部来传入依赖的方式,我们就称为依赖注入。 现在我们发现上面 1 中存在的两个问题都很好解决了,简单的说依赖注入主要有两个好处: 1、解耦,将依赖之间解耦 2、因为已经解耦,所以方便做单元测试,尤其是 Mock 测试 * 控制反转和依赖注入的关系 * 我们已经分别解释了控制反转和依赖注入的概念。有些人会把控制反转和依赖注入等同,但实际上它们有着本质上的不同。 * **控制反转**是一种思想 * **依赖注入**是一种设计模式 * **C#2.0~3.0** * 泛型 * 泛型可以防止代码膨胀,最大限度的保证代码的重用性,还可以保护类型安全和提高性能 * 典型案例 `ArrayList=>List<T>` * 泛型约束 ``` public class Base<T> where T : Base<T> { public T inst { get; set; } } public class ChildCls : Base<ChildCls> { } ``` * 经验谈 * 底层、通用的代码用的多 * 逻辑层 UI 层只需要会用 List、Dictionary 的程度就行 * 如果自己写框架和库,泛型的深入用法必不可少 * 偏僻知识点 * 获取带有泛型类的类型 ``` var t = typeof(Dictionary<,>); Debug.Log(t); //System.Collections.Generic.Dictionary`2[TKey,TValue] ``` * partial 关键字 * 将类拆分成不同部分可以在不同类文件甚至不同命名空间内实现 * 也可以放在方法上 ``` public partial class Person { public void Say() { Hello(); } //先在一个类里声明 partial void Hello(); } public partial class Person { //在另一个partial类里实现 partial void Hello() { Debug.Log("Fuck"); } } ``` * 匿名方法,可空值类型 * 匿名方法 ``` private Action<int> func; void Start() { //1.0委托只能支持方法 func = MyFunc; //2.0可以支持匿名方法 func = delegate(int i) { Debug.Log("2.0"); }; } private void MyFunc(int a) { Debug.Log("1.0"); } ``` * 可空值类型`int? a = null;`值类型后加个? * 迭代器 ``` public class MyEnumerable:IEnumerable { private int[] arr = {1, 2, 3}; public MyEnumerable() { } public IEnumerator GetEnumerator() { // return new MyEnumerator(arr.Length, arr); for (int i = 0; i < arr.Length; i++) { yield return arr[i]; } } } public class MyEnumerator:IEnumerator { private int idx = -1; private int[] data; private int max = 0; public MyEnumerator(int max,int[] data) { this.max = max; this.data = data; } public bool MoveNext() { idx++; return idx < max; } public void Reset() { idx = -1; } public object Current { get { return data[idx]; } } } void Start() { var a = new MyEnumerable(); foreach (var i in a) { print(i); } } ``` * 字典的实现原理 * 对于 Dictionary 的实现原理,其中有两个关键的算法,一个是 **Hash** 算法,一个是用于应对 Hash 碰撞**冲突解决**算法。 * Hash 算法 * Hash 算法是一种**数字摘要**算法,它能将不定长度的二进制数据集给**映射**到一个较短的二进制长度数据集,常见的 MD5 算法就是一种 Hash 算法,通过 MD5 算法可对任何数据生成数字摘要。而实现了 Hash 算法的函数我们叫她 **Hash 函数**。Hash 函数有以下几点特征。 1. 相同的数据进行 Hash 运算,得到的结果一定相同。`HashFunc(key1) == HashFunc(key1)` 2. 不同的数据进行 Hash 运算,其结果也可能会相同,(**Hash 会产生碰撞**)。`key1 != key2 => HashFunc(key1) == HashFunc(key2)`. 3. Hash 运算时不可逆的,不能由 key 获取原始的数据。`key1 => hashCode`但是`hashCode ==> key1`。 * 常见的构造 Hash 函数的算法有以下几种。 **1. 直接寻址法:**取 keyword 或 keyword 的某个线性函数值为散列地址。即 H(key)=key 或 H(key) = a•key + b,当中 a 和 b 为常数(这样的散列函数叫做自身函数) **2. 数字分析法:**分析一组数据,比方一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体同样,这种话,出现冲突的几率就会非常大,可是我们发现年月日的后几位表示月份和详细日期的数字区别非常大,假设用后面的数字来构成散列地址,则冲突的几率会明显减少。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。 **3. 平方取中法:**取 keyword 平方后的中间几位作为散列地址。 **4. 折叠法:**将 keyword 切割成位数同样的几部分,最后一部分位数能够不同,然后取这几部分的叠加和(去除进位)作为散列地址。 **5. 随机数法:**选择一随机函数,取 keyword 的随机值作为散列地址,通经常使用于 keyword 长度不同的场合。 **6. 除留余数法:**取 keyword 被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅能够对 keyword 直接取模,也可在折叠、平方取中等运算之后取模。对 p 的选择非常重要,一般取素数或 m,若 p 选的不好,容易产生碰撞.(**C# 用的就是这种,后面贴源码**) * Hash 桶算法 * 说到 Hash 算法大家就会想到 **Hash 表**,一个 Key 通过 Hash 函数运算后可快速的得到 hashCode,通过 hashCode 的映射可直接 Get 到 Value,但是 hashCode 一般取值都是非常大的,经常是 2^32 以上,不可能对每个 hashCode 都指定一个映射。 * 因为这样的一个问题,所以人们就将生成的 HashCode 以分段的形式来映射,把每一段称之为一个 **Bucket(桶)**,一般常见的 Hash 桶就是直接对结果取余。 * 解决冲突算法 * 对于一个 hash 算法,不可避免的会产生冲突,那么产生冲突以后如何处理,是一个很关键的地方,目前常见的冲突解决算法有**拉链法 (Dictionary 实现采用的)**、开放定址法、再 Hash 法、等等 **1. 拉链法:**这种方法的思路是将产生冲突的元素建立一个单链表,并将头指针地址存储至 Hash 表对应桶的位置。这样定位到 Hash 表桶的位置后可通过遍历单链表的形式来查找元素。 **2. 再 Hash 法:**顾名思义就是将 key 使用其它的 Hash 函数再次 Hash,直到找到不冲突的位置为止。(但是再 Hsah 的值难免会再碰撞,还需要再 hash) * Dictionary 实现 * Entry 结构体 ``` //首先我们引入Entry这样一个结构体,它的定义如下代码所示。这是Dictionary种存放数据的最小单位,调用Add(Key,Value)方法添加的元素都会被封装在这样的一个结构体中 private struct Entry { public int hashCode; // 除符号位以外的31位hashCode值, 如果该Entry没有被使用,那么为-1 public int next; // 下一个元素的下标索引,如果没有下一个就为-1 public TKey key; // 存放元素的键 public TValue value; // 存放元素的值 } ``` * 其它关键私有变量 ``` //除了Entry结构体外,还有几个关键的私有变量,其定义和解释如下代码所示。 private int[] buckets; // Hash桶 private Entry[] entries; // Entry数组,存放元素 private int count; // 当前entries的index位置 private int version; // 当前版本,防止迭代过程中集合被更改 private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的 private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置 private IEqualityComparer<TKey> comparer; // 比较器 private KeyCollection keys; // 存放Key的集合 private ValueCollection values; // 存放Value的集合 ``` * Add ``` private void Insert(TKey key, TValue value, bool add) { if( key == null ) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); } if (buckets == null) Initialize(0); //初始化上面的那些字段 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; int targetBucket = hashCode % buckets.Length; //通过哈希值和取余法获取对应的目标Bucket //寻找是否有相同key的元素 for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) { if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) { if (add) { ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate); } entries[i].value = value; version++; return; } } int index; if (freeCount > 0) { //判断现在是否有空闲的元素,优先使用空闲的元素 index = freeList; freeList = entries[index].next; freeCount--; } else { if (count == entries.Length) //判断是否存储的项和Entries的长度,相等的话,就重新扩容。 { Resize();// 扩容Buctet和Entries的大小 targetBucket = hashCode % buckets.Length; } index = count; count++; } entries[index].hashCode = hashCode; entries[index].next = buckets[targetBucket]; entries[index].key = key; entries[index].value = value; buckets[targetBucket] = index; version++; } ``` 1. 初次添加元素时,如果构造函数中不传入大小,默认会自动取一个最小的质数(即:3)来作为桶的大小和元素集合的大小,并且初始换里面的字段变量。 2. 在寻找元素插入的位置的时候,首先通过元素的 hashcode % bucket 的长度优先得到要插入的目标的 Bucket 是哪个,然后将元素的 hashCode 和 next 赋值。 3. 这里 next 赋值的话详细说一下。首先,我们先分析 buckets,它里面的每个 bucket 保存的是对应链表最后一个元素的下标,可以通过最后一行代码得知,每次给元素赋值之后,当前元素的下标,会赋值给对应的 bucket。 而每个新插入元素,只需要当前 bucket 里面的值赋值给它当前的 next 指向的 index 就可以了。 > [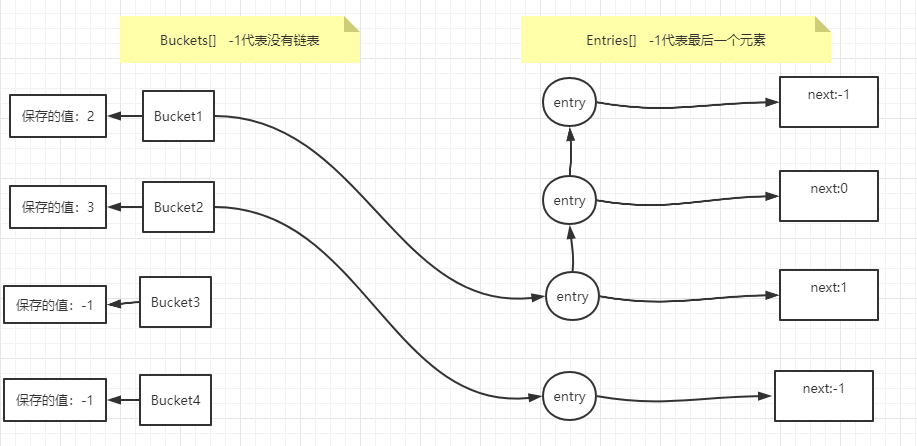](https://img2020.cnblogs.com/blog/2078617/202009/2078617-20200904112706118-1780879618.png) * Find ``` private int FindEntry(TKey key) { if( key == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); } if (buckets != null) { int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; //首先获取key的hashCode //寻址的第一个元素就是对应目标桶里面记录的index,然后通过对应元素的next指向下一个元素,当next为-1时,就是代表已经到最后一个元素了。 for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) { //判断元素的hashcode和key是否都相等。 if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i; } } return -1; } ``` 1. 是先找到目标桶,因为目标桶里面记录的是它对应链表的最后一个元素的下标,然后顺着元素的 next 找,直到找到这个元素为止。 2. 可以仔细想想,这样的话,每次查找就可以过滤一大批的数据,所以查的速度就更快了,但是当数据量大的时候,也是会有效率问题。 [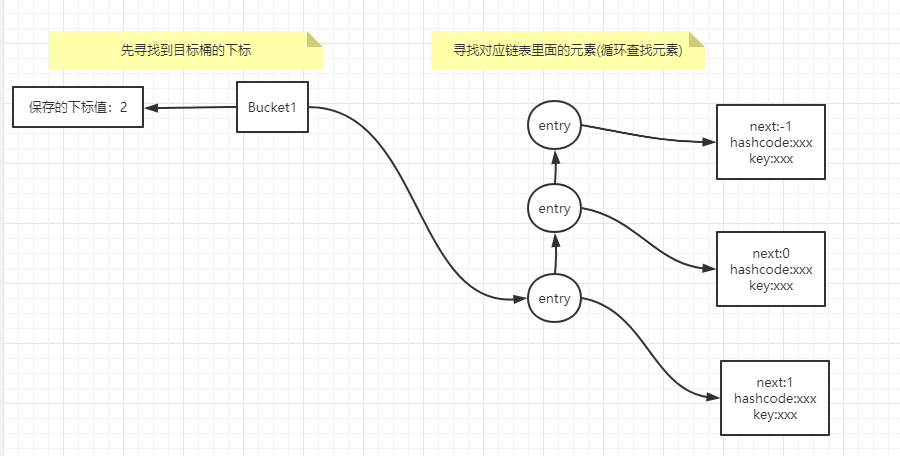](https://img2020.cnblogs.com/blog/2078617/202009/2078617-20200904120136964-1719401217.png) * Remove ``` public bool Remove(TKey key) { if(key == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); } if (buckets != null) { int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; int bucket = hashCode % buckets.Length; int last = -1; //这个变量主要是记录上一个元素的下标。 //和上面一样,先查找要删除的元素。 for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) { if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) { if (last < 0) { //代表第一个元素就是要找的元素 buckets[bucket] = entries[i].next; //把buctet指向的下标,指向下一个元素 } else { entries[last].next = entries[i].next; //将上一个元素的下标,指向下一个元素的下标,去掉被删除的元素。 } entries[i].hashCode = -1; entries[i].next = freeList; //当前元素指向上一个空闲元素的下标 entries[i].key = default(TKey); entries[i].value = default(TValue); freeList = i; //记录最后一个被移除元素的下标 freeCount++; //每次移除,空闲的元素+1 version++; return true; } } } return false; } ``` 1. 查找对应的元素和上面的逻辑其实是一样的,它这里定义了一个变量,用来记录上一个元素的下标。 2. 当找到对应的元素时,把上个元素的 next 指向当前被移除元素的 next,即把当前被移除的元素跳过去。 3. 然后将被移除元素的字段初始化,需要注意的是这个 next 的值,它用的是 freelist,记录最后一个被移除元素的 index,每移除一个元素,被移除的元素数量就 + 1,即 freecount。 被移除的元素也会形成一个链表,它的 next 首部元素 next 指向 - 1,后边被移除的元素 next 指向上一个被移除元素的 index。 4. 回过头再去看添加的时候,它会判断,freeCount 的数量是否是大于 0 的,如果大于 0 的话,优先使用被移除元素的位置并填充它们,它的 index 就是 freeList, 然后再把当前元素的 next 赋值给 freelist(即下次再插入元素的时候,就是上一个被移除元素的下标)。 5. 最后在下面给当前元素赋值的时候,它的 next 又指向当前 bucket 里面的值,即作为对应链表的尾部。 [](https://img2020.cnblogs.com/blog/2078617/202009/2078617-20200904130835040-13541705.png) * Resize 操作 (扩容) ``` private void Resize(int newSize, bool forceNewHashCodes) { Contract.Assert(newSize >= entries.Length); // 这个newSize是获取大于count的最小质数 int[] newBuckets = new int[newSize]; for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1; //初始化每个bucket的值 Entry[] newEntries = new Entry[newSize]; Array.Copy(entries, 0, newEntries, 0, count); //将原来的entries的值copy到新的entries里面 for (int i = 0; i < count; i++) { if (newEntries[i].hashCode >= 0) { //判断hashcode代表是有效的entry int bucket = newEntries[i].hashCode % newSize; newEntries[i].next = newBuckets[bucket]; newBuckets[bucket] = i; //上面的操作就是重新找新的桶,然后重新给entey的next赋值。 } } buckets = newBuckets; entries = newEntries; } ``` 1. 这里的 newSize 会在里面的元素数达到 entries 的长度是扩容,它是在一个 helper 类里面进行取值,它是拿大于它的最小质数。 2. 这个新的 size 就是 buckets 的长度和 entries 的长度,先把原来的 entries 的值 copy 到新的 entries 里面。 3. 然后循环新的的 entries,重新定义新的桶的值并且给原来的数据,重新形成新的链表。 * 再谈 Add 操作 * 实际上 **Add** 操作会优先使用`freeList`的空闲`entry`位置 * 因为`count`是通过自增的方式来指向`entries[]`下一个空闲的`entry`,如果有元素被删除了,那么在`count`之前的位置就会出现一个空闲的`entry`;如果不处理,会有很多空间被浪费。 * 这就是为什么 **Remove** 操作会记录`freeList、freeCount`,就是为了将删除的空间利用起来。 * Collection 版本控制 * 在上文中一直提到了`version`这个变量,在每一次新增、修改和删除操作时,都会使`version++`;那么这个`version`存在的意义是什么呢? 首先我们来看一段代码,这段代码中首先实例化了一个 Dictionary 实例,然后通过`foreach`遍历该实例,在`foreach`代码块中使用`dic.Remove(kv.Key)`删除元素。 ``` Dictionary<int,string> dic = new Dictionary<int, string>(); dic.Add(1,"1"); dic.Add(2,"1"); dic.Add(3,"1"); foreach (var kAv in dic) { dic.Remove(kAv.Key); } //Collection was modified; enumeration operation may not execute ``` * 结果就是抛出了`System.InvalidOperationException:"Collection was modified..."`这样的异常,**迭代过程中不允许集合出现变化**。如果在 Java 中遍历直接删除元素,会出现诡异的问题,所以. Net 中就使用了`version`来实现版本控制。 那么如何在迭代过程中实现版本控制的呢?我们看一看源码就很清楚的知道。 ``` public bool MoveNext() { if (this.version != this.dictionary.version) ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion); for (; (uint) this.index < (uint) this.dictionary.count; ++this.index) { if (this.dictionary.entries[this.index].hashCode >= 0) { this.current = new KeyValuePair<TKey, TValue>(this.dictionary.entries[this.index].key, this.dictionary.entries[this.index].value); ++this.index; return true; } } this.index = this.dictionary.count + 1; this.current = new KeyValuePair<TKey, TValue>(); return false; } ``` * 在迭代器初始化时,就会记录`dictionary.version`版本号,之后每一次迭代过程都会检查版本号是否一致,如果不一致将抛出异常。 **这样就避免了在迭代过程中修改了集合,造成很多诡异的问题。** * lua 和 C# 的交互 * 为什么要装箱和拆箱 * 概述 * 简单来说装箱是将值类型转换为引用类型 ;拆箱是将引用类型转换为值类型 * 装箱:用于在垃圾回收堆中储存值类型。装箱是值类型到 Object 类型或到此类型所实现的任何接口类型的隐式转换。 ``` void Start() { MyFunc(1); } public void MyFunc(Object o) { print(o); } //将值类型转换为了引用类型System.Int32 ``` * 拆箱:从 object 类型到值类型或从接口类型到实现该接口的值类型的显示转换。 ``` void Start() { int i = 1; Int32 j = i; i = 2; print(i); print(j); } //2 //1 ``` * 装箱和拆箱的内部操作是什么样的? * .NET 中,数据类型划分为 值类型 和 引用 (不等同于 C++ 的指针) 类型 ,与此对应,内存分配被分成了两种方式,一为栈,二为堆,注意:是托管堆。 值类型只会在栈中分配。 引用类型分配内存与托管堆。(托管堆对应于垃圾回收。) * **o 和 i 的改变将互不影响,因为装箱使用的是 i 的一个副本。** * 装箱: 1:首先从托管堆中为新生成的引用对象分配内存 (大小为值类型实例大小加上一个方法表指针和一个 SyncBlockIndex)。 2:然后将值类型的数据拷贝到刚刚分配的内存中。 3:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。 可以看出,进行一次装箱要进行分配内存和拷贝数据这两项比较影响性能的操作。 * 拆箱: 1:首先获取托管堆中属于值类型那部分字段的地址,这一步是严格意义上的拆箱。 2:将引用对象中的值拷贝到位于线程堆栈上的值类型实例中。 经过这 2 步,可以认为是同 boxing 是互反操作。严格意义上的拆箱,并不影响性能,但伴随这之后的拷贝数据的操作就会同 boxing 操作中一样影响性能。 * 为什么要进行装箱和拆箱? * 作用:为了保证通用性和提高系统性能 * 一种最普通的场景是,调用一个含类型为 Object 的参数的方法,该 Object 可支持任意为型,以便通用。当你需要将一个值类型 (如 Int32) 传入时,需要装箱。 * 另一种用法是,一个非泛型的容器,同样是为了保证通用,而将元素类型定义为 Object。于是,要将值类型数据加入容器时,需要装箱。 * 装箱 / 拆箱对执行效率的影响 * 显然,从原理上可以看出,装箱时,生成的是全新的引用对象,这会有时间损耗,也就是造成效率降低。 那该如何做呢? 首先,应该尽量避免装箱。 * 比如上例 2 的两种情况,都可以避免,在第一种情况下,可以通过重载函数来避免 * 第二种情况,则可以通过泛型特化来避免。 * 当然,凡事并不能绝对,假设你想改造的代码为第三方程序集,你无法更改,那你只能是装箱了。 对于装箱 / 拆箱代码的优化,由于 C# 中对装箱和拆箱都是隐式的,所以,根本的方法是对代码进行分析,而分析最直接的方式是了解原理结何查看反编译的 IL 代码。比如:在循环体中可能存在多余的装箱,你可以简单采用提前装箱方式进行优化。 * 对装箱 / 拆箱更进一步的了解 * 装箱 / 拆箱并不如上面所讲那么简单明了,比如:装箱时,变为引用对象,会多出一个方法表指针,这会有何用处呢? 我们可以通过示例来进一步探讨。 ``` struct A:ICloneable { public Int32 x; public override String ToString() { return String.Format("{0}",x); } public object Clone() { return MemberwiseClone(); } } void Start() { A a; a.x = 100; print(a.ToString()); //a.ToString()。编译器发现A重写了ToString方法,会直接调用ToString的指令。因为A是值类型,编译器不会出现多态行为。因此,直接调用,不装箱。(注:ToString是A的基类System.ValueType的方法) print(a.GetType()); //a.GetType(),GetType是继承于System.ValueType的方法,要调用它,需要一个方法表指针,于是a将被装箱,从而生成方法表指针,调用基类的System.ValueType。(补一句,所有的值类型都是继承于System.ValueType的)。 A a2 = (A)a.Clone(); //a.Clone(),因为A实现了Clone方法,所以无需装箱。 ICloneable c = a2; //ICloneable转型:当a2为转为接口类型时,必须装箱,因为接口是一种引用类型。 Object o = c.Clone();//c.Clone()。无需装箱,在托管堆中对上一步已装箱的对象进行调用。 /*其实上面的基于一个根本的原理,因为未装箱的值类型没有方法表指针,所以,不能通过值类型来调用其上继承的虚方法。另外,接口类型是一个引用类型。对此,我的理解,该方法表指针类似C++的虚函数表指针,它是用来实现引用对象的多态机制的重要依据。*/ } ``` * 如何更改已装箱的对象 * 对于已装箱的对象,因为无法直接调用其指定方法,所以必须先拆箱,再调用方法,但再次拆箱,会生成新的栈实例,而无法修改装箱对象。有点晕吧,感觉在说绕口令。还是举个例子来说:(在上例中追加 change 方法) ``` struct A { public Int32 x; public override String ToString() { return String.Format("{0}",x); } public void Change(Int32 x) { this.x = x; } } interface IChange { void Change(Int32 x); } struct B : IChange { public Int32 x; public override String ToString() { return String.Format("{0}",x); } public void Change(int x) { this.x = x; } } void Start() { A a ; a.x = 100; Object o = a; //装箱成o,下面,想改变o的值。 // o.Change(300); //报错,因为o没有change方法 ((A)o).Change(200); print(o);//100 没改变 /* 没改掉的原因是o在拆箱时,生成的是临时的栈实例A,所以,改动是基于临时A的,并未改到装箱对象。 (附:在托管C++中,允许直接取加拆箱时第一步得到的实例引用,而直接更改,但C#不行。) */ //那该如何是好? //嗯,通过接口方式,可以达到相同的效果。 B b; b.x = 100; o = b; ((IChange)o).Change(200); print(o);//200 //在将o转型为IChange时,这里不会进行再次装箱,当然更不会拆箱,因为o已经是引用类型,再因为它是IChange类型,所以可以直接调用Change,于是,更改的也就是已装箱对象中的字段了,达到期望的效果。 } ``` 参考资料 ---- * C# 程序设计视频教程 * C# 笔记 * 垃圾回收算法详解(引用计数 / 标记 - 清除 / 标记压缩 / 复制算法) * C# 技术漫谈之垃圾回收机制 (GC) * 浅析 C# Dictionary 实现原理 * C# 装箱和拆箱(Boxing 和 UnBoxing) __EOF__ C# 知识树整理——内存探索 C#的内存分配探索