Compute Shader 进阶应用:结合Hi-Z 剔除海量草渲染 agile Posted on Oct 2 2021 优秀博文 > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [zhuanlan.zhihu.com](https://zhuanlan.zhihu.com/p/278793984) **为什么能加速 Hi-Z** --------------- Hi-Z 是各种实时剔除中 比较高效的一种,因为一般是在 cpu 端直接剔除,顶点完全不提交 gpu,比 Z-Prepass 或 early-z 这种仅仅减少 ps 量 但不能减少 vs 计算量的方式收益大很多。但是因为在 cpu 端剔除 就涉及深度图从 gpu 回读到 cpu 问题,这个是性能杀手。 虽然可以做分帧回读,但会让延迟更大,误裁剪问题加重。另一个选择是 GPU Driven RP 那么就避免了回读,但整个管线这样修改风险太高且很多团队不具备这样的开发能力。所以 对于特殊应用 单独的 Compute Shader 裁剪 + Hi-Z,就可以得到同样好处却开发简单很多。比如 海量的草渲染。 **先看最终效果** ---------- 这是普通的视锥裁剪后提交给 gpu 的数据量 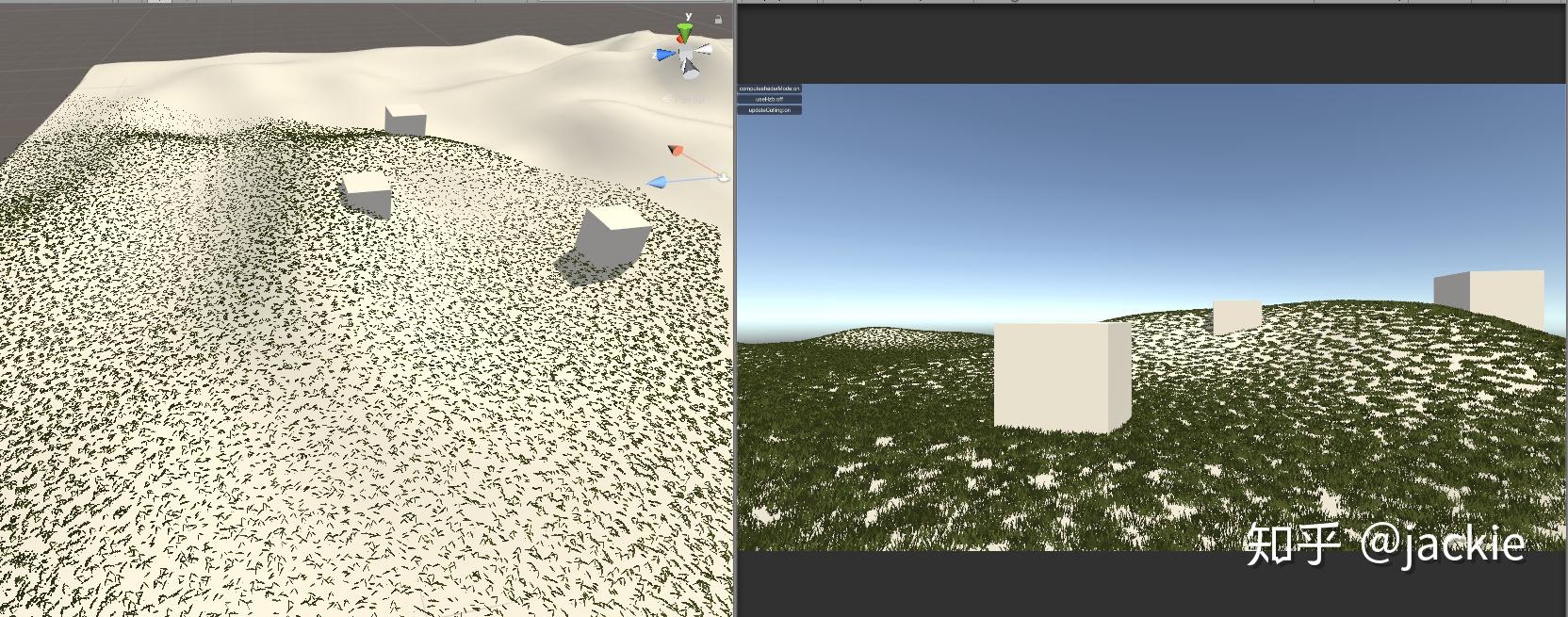 这是 Hi-Z 结合 Compute Shader 裁剪后 提交给 gpu 的数据量 最终渲染画面不变,但提交量少很多 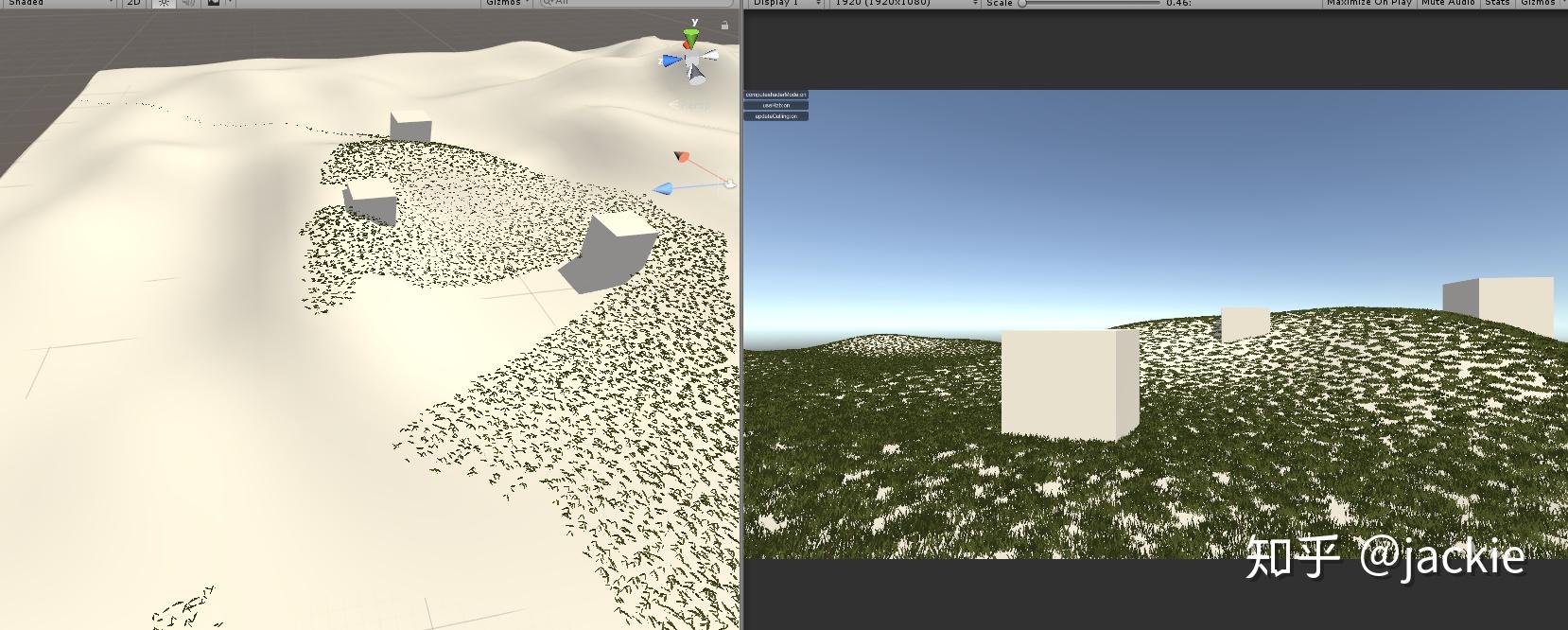 这是没做 Hi-Z 的画面与帧数  这是做了 Hi-Z 结合 Compute Shader 裁剪后的画面与帧数  _在 9600kf rx590 显卡 上可以节省 0.5ms 的渲染时间,在建筑 树木多的环境可以获得更多提升_ 为什么草要用 Hi-Z ----------- 多年以来海量的草的渲染一直是实时渲染中的一个难题,不管是 AAA 大厂 还是小团队都没有很好的解决它,孤岛惊魂 5 以及新曙光等所有大作 也都是控制在一个较小范围内的渲染。它困难在哪呢?最主要是 overdraw 严重(公告板草) 和顶点数太多(模型草)。而且常规剔除方案都会大打折扣。 我们知道常规剔除方式有这几大类 :逐对象剔除,逐三角形剔除,逐像素剔除。 逐对象剔除问题,因为 terrain 的草渲染是 8 平方米 (8 可调)合并成一个静态 mesh 来渲染否则 drawcall 太多。这样导致一个 mesh 体积较大 很难出现整个 mesh 都看不见的情况 所以逐对象剔(传统 hi-z,或 **PVS**)除几乎没收益。逐三角形剔除又只有在 GPU Driven Pipeline 下才有价值, 且草如果不合并 每棵草三角形很少不如逐对象剔除。 逐像素剔除问题,比如 zprepass 剔除,特别适合 ps 计算很复杂的渲染对象,这样增加下 vs 计算(多一次顶点计算绘制深度图)减少 ps 计算量是划算的。但草多的是 vs,ps 比较简单不是主要瓶颈,所以这种剔除收益不大。 传统剔除优化不大与至于发展出 完全跳过定点数瓶颈的 屏幕空间草绘制,特别适合较短的草。 所以考虑下来, Compute Shader 单棵草裁剪 + Hi-Z 成了目前团队已知的最符合项目需求的方案了。 Hi-Z 深度图创建 ---------- Hi-Z 原理很简单,就是根据物体的包围盒所在的屏幕坐标与深度图比较深度 如果被挡住就不提交数据给 gpu 渲染,一般是采用和上一帧深度图对比 避免重新绘制一遍场景深度。逻辑上是 包围盒覆盖的像素点 挨个都挡住物体,就裁剪物体。但这样需要对比很多个像素性能很差,所以提出了 Hi-Z 概念。就是把深度图创建出多个 mipmaps,mip0 就是 原始深度图信息,mip1 就是 1/4 mip0 面积大小,4 个 mip0 像素 取最远离相机的那个值写入一个 mip1 像素,mip2 同理不断创建更低精度的图。这样一个物体包围盒 如果是在 mip0 图上 占据 16x16 像素。就不用对比 256 次了,只需要 找到 mip4 上一个像素就可以了,因为这一个像素记录的是这 16x16 像素最远离相机的深度 如果它都挡住了物体那么 那么其他的像素更靠近相机 肯定就能确定整个物体都被挡住了,可以进行剔除了。需要的 shader 算法如下,为什么是 0.25 偏移而不是 0.5 这是因为贴图尺寸的传入 是 输出的图尺寸刚好是 采样的图的一半。 ``` inline float HZBReduce(sampler2D mainTex, float2 inUV, float2 invSize) { float4 depth; float2 uv0 = inUV + float2(-0.25f, -0.25f) * invSize; float2 uv1 = inUV + float2(0.25f, -0.25f) * invSize; float2 uv2 = inUV + float2(-0.25f, 0.25f) * invSize; float2 uv3 = inUV + float2(0.25f, 0.25f) * invSize; depth.x = tex2D(mainTex, uv0); depth.y = tex2D(mainTex, uv1); depth.z = tex2D(mainTex, uv2); depth.w = tex2D(mainTex, uv3); #if defined(UNITY_REVERSED_Z) return min(min(depth.x, depth.y), min(depth.z, depth.w)); #else return max(max(depth.x, depth.y), max(depth.z, depth.w)); #endif } ``` 渲染多个 mipmaps 的代码逻辑在这里,因为 blit 不支持直接往某个 mipmap 上读写 所以需要 copy 转一下,且缓存上一次输出结果作为下一次输入贴图。当然第一次 拷贝对象的尺寸相同所以直接 blit 就好 不需要用 shader 降采样。因为少于 8 像素的用途不大所以我自己控制了下渲染次数。 ``` int w = hzbDepth.width; int h = hzbDepth.height; int level = 0; RenderTexture lastRt = null; RenderTexture tempRT; while (h > 8) { hzbMat.SetVector(ID_InvSize, new Vector4(1.0f / w, 1.0f / h, 0, 0)); tempRT = RenderTexture.GetTemporary(w, h, 0, hzbDepth.format); tempRT.filterMode = FilterMode.Point; if (lastRt == null) { Graphics.Blit(Shader.GetGlobalTexture("_CameraDepthTexture"), tempRT); } else { hzbMat.SetTexture(ID_DepthTexture, lastRt); Graphics.Blit(null, tempRT, hzbMat); RenderTexture.ReleaseTemporary(lastRt); } Graphics.CopyTexture(tempRT, 0, 0, hzbDepth, 0, level); lastRt = tempRT; w /= 2; h /= 2; level++; } ``` Compute Shader 剔除 ----------------- **compute shader 文件内说明** _1、变量解释_  posAllBuffer 是地形上 200*200 平方米 所有草的 position 数组。 posVisibleBuffer 是剔除后 真正可见 需要渲染的 那些 position 数组。 bufferWithArgs 是 Graphics.DrawMeshInstancedIndirect 需要的参数 传递渲染的单个实例的三角形索引数量 和 这一次调用要渲染的实例数量。因为 前者是固定不变的 ,后者每帧都会不同,所以传给 compute shader 直接写入计算结果,避免回 cpu 再传效率会高些。 cmrPos 是相机位置 cmrDir 是相机朝向 cmrHalfFov 是相机 fov 的一半,用来计算 某棵草在 mip0 深度图上占据的 像素数量 从而计算出 选哪一级 mipmap 进行深度对比。是一个简单的 tan 关系 matrix_VP 就是 UNITY_MATRIX_MVP 的 VP 部分,compute shader 不像普通 shader 传递了一堆渲染变量,所以需要什么自己传。我用来做视锥裁剪的,其实可以不需要它,视锥裁剪有很多种方法。我是因为 一开始计算哪一级 mipmap 时,直接把草边界坐标也通过 matrix_VP 转到屏幕空间 对比草中心点的屏幕空间 直接获得屏幕上像素跨度。后面这个计算优化了,但测了这部分开销很少就没改视锥裁剪算法了。 HZB_Depth 就是上面创建好的带 mipmaps 的深度图。 2、函数解释 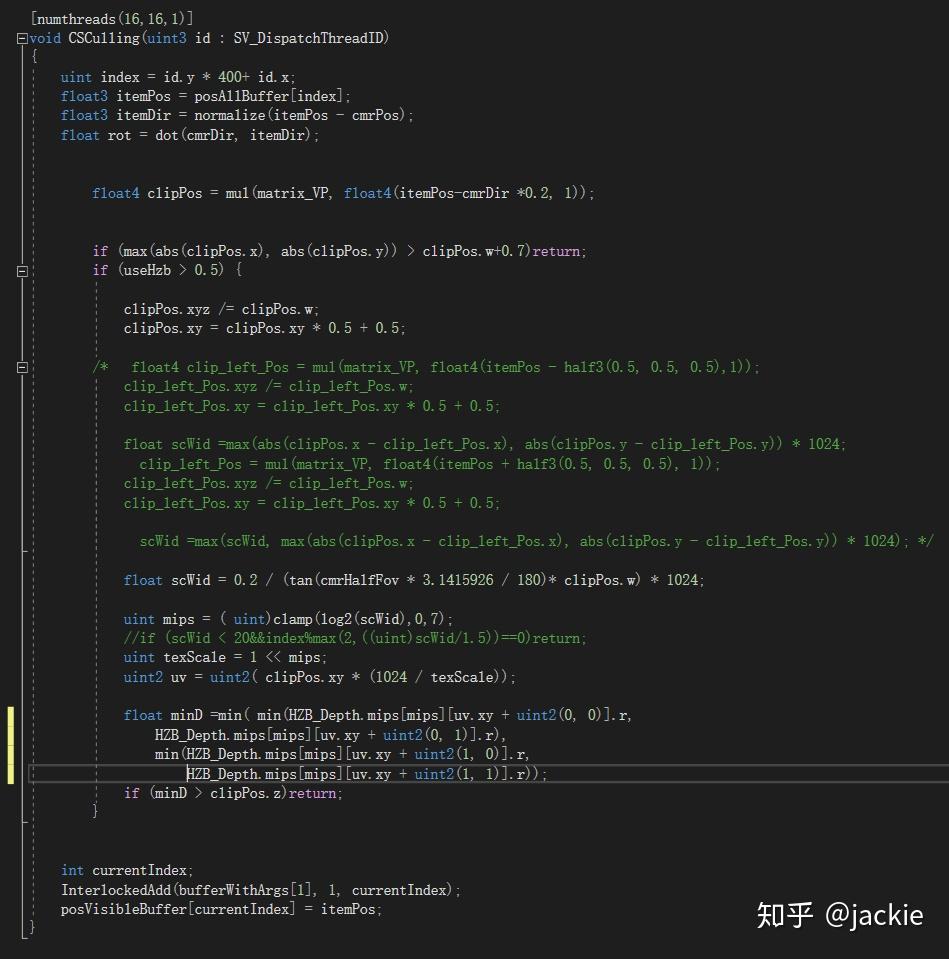 * 400 是 400x400 棵数组的草 * float4 clipPos = mul(matrix_VP, float4(itemPos-cmrDir *0.2, 1)); 往相机向移动 0.2 米,因为把没棵草看成半径 0.2 米的球体。所以判断遮挡位置不是 草中心点 而是 靠近相机的表面。 * 视锥裁剪方法很多 粗略的 float rot = dot(cmrDir, itemDir); 然后计算 rot>0.7 比如 就可以快速判断出是否可见,精确的裁剪可以用常用的 视锥 6 个面挨个判断与面空间关系。我这里用 max(abs(clipPos.x), abs(clipPos.y)) > clipPos.w+0.7 . 原理是 [clipPos.xyz/clipPos.w](http://clippos.xyz/clipPos.w) 后 [-1,1] 范围内的才会可见。对于部分可见的部分 根据草的大小,设置了 0.7 的外扩范围。 * 多行注释部分 是我原来 取草所在 aabb 2 个顶点转到屏幕空间的像素差 后面改用 float scWid = 0.2 / (tan(cmrHalfFov * 3.1415926 / 180)* clipPos.w) * 1024; 计算了,画个图就能理解这种比例关系。 * if (scWid < 20&&index%max(2,((uint)scWid/1.5))==0)return; 是实际项目优化用的 会让远处的草慢慢减少密度 因为他们占据画面小 贡献度低,但顶点数却很难减少了(做草的 lod 也没用 每个草少一个点都改形转了 除非做 hlod) * minD 就是取草占据的 4 个位置 最小值。最远的那个位置最远都挡住草那更近的肯定也挡住,但这里用 min 还 max 看深度图存储方式 近为 0 还是 1 这个需要用 UNITY_REVERSED_Z 区分除非能确定自己所用的平台下 unity 都采用 反转或不反转。 * 最后 3 句是写入部分 为了避免同时写一个数组索引位置,所以用了 InterlockedAdd,它可以确保 并行的 culling 函数 会有序的进行累加得到唯一的数组索引。我经过测试这比 专门为此设计的 ComputeBufferType.Append 性能还高些。 **代码文件说明** 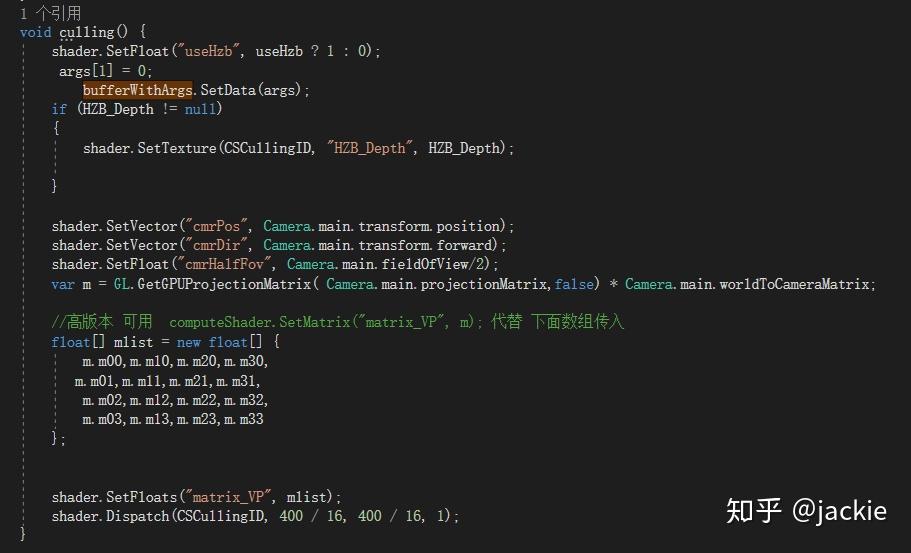 这部分比较简单 就是每帧清空需要渲染的数量为 0 ,传入深度图,关键点是传 matrix 我所以在版本 没用这个接口 需要用 float 数组代替 **动态裁剪结果** 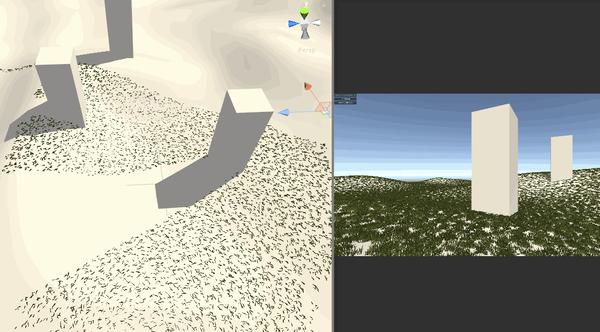 这种裁剪幅度就比自带草 或合皮 mesh 的草 剔除力度大多了。(如果不合批 drawcall 又爆炸) geometry shader 剔除 ------------------ 做完 computeshader 剔除后, 我想到 如果在 geometry shader 做 Hi-z 遮挡剔除会如何呢? 剔除的顶点就不创建出草. 这里不放结果了, 因为引擎大佬 @吕文伟 强烈建议我不要用 gs, 简单的实测结果是 1060 卡上 gs 和 cs 性能差不多甚至反超 1,2 帧, 但在 660 等低端显卡上 gs 落后 8,9 帧, 总体说了不建议采用. 除非你的平台或特殊原因不能用 cs. 核心代码如下 ``` //一个三角面生成的最多顶点数 [maxvertexcount(84)]//tris x3 void geom(point v2g IN[1], inout TriangleStream<g2f> tristream) { g2f o; float dis = mul(UNITY_MATRIX_MV, IN[0].vertex).z; if (-dis > 70 || dis > 0) { return; } float4 clipPos = UnityObjectToClipPos(IN[0].vertex); if (max(abs(clipPos.x), abs(clipPos.y)) > clipPos.w + 0.7) { return; } #ifdef USE_HZB clipPos.xyz /= clipPos.w; clipPos.xy = clipPos.xy * 0.5 + 0.5; float cmrHalfFov = 30; float scWid = 0.2 / (tan(cmrHalfFov * 3.1415926 / 180) * clipPos.w) * 1024; uint mips = (uint)clamp(log2(scWid), 0, 7); //if (scWid < 20)return; uint texScale = 1 << mips; #if UNITY_UV_STARTS_AT_TOP clipPos.y = 1 - clipPos.y; #endif float minD = min(min(tex2Dlod(HZB_Depth_Tex, float4(clipPos.xy + float2(0, 0) * texScale / 1024, mips, 0)).r, tex2Dlod(HZB_Depth_Tex, float4(clipPos.xy + float2(0, 1) * texScale / 1024, mips, 0)).r), min(tex2Dlod(HZB_Depth_Tex, float4(clipPos.xy + float2(1, 0) * texScale / 1024, mips, 0)).r, tex2Dlod(HZB_Depth_Tex, float4(clipPos.xy + float2(1, 1) * texScale / 1024, mips, 0)).r)); if (minD > clipPos.z) { //tristream.RestartStrip(); return; } #endif for (int i = 0; i < 84; i++) {//tris x3 o.vertex = UnityObjectToClipPos(IN[0].vertex + GrassMesh1[(int)GrassTris1[i]]); o.uv = GrassMesh1[(int)GrassTris1[i] + 42].xy;///vets tristream.Append(o); } tristream.RestartStrip(); } ``` **以下是完整的项目资源连接** [jackie2009/HiZ_grass_culling](https://github.com/jackie2009/HiZ_grass_culling) 项目落地情况 ------ 这是我参与开的端游《生死狙击 2》实际效果 gtx660 低端机上减少 1ms 渲染. 帮助低端机帧率达标. 游戏在 11 月 20 日开始第四次技术测试 欢迎大家来玩 一起讨论相关技术, 祝测试顺利!. [《生死狙击 2 》官方网站 - 国产次世代射击端游火爆预约中](https://www.ssjj.cn/)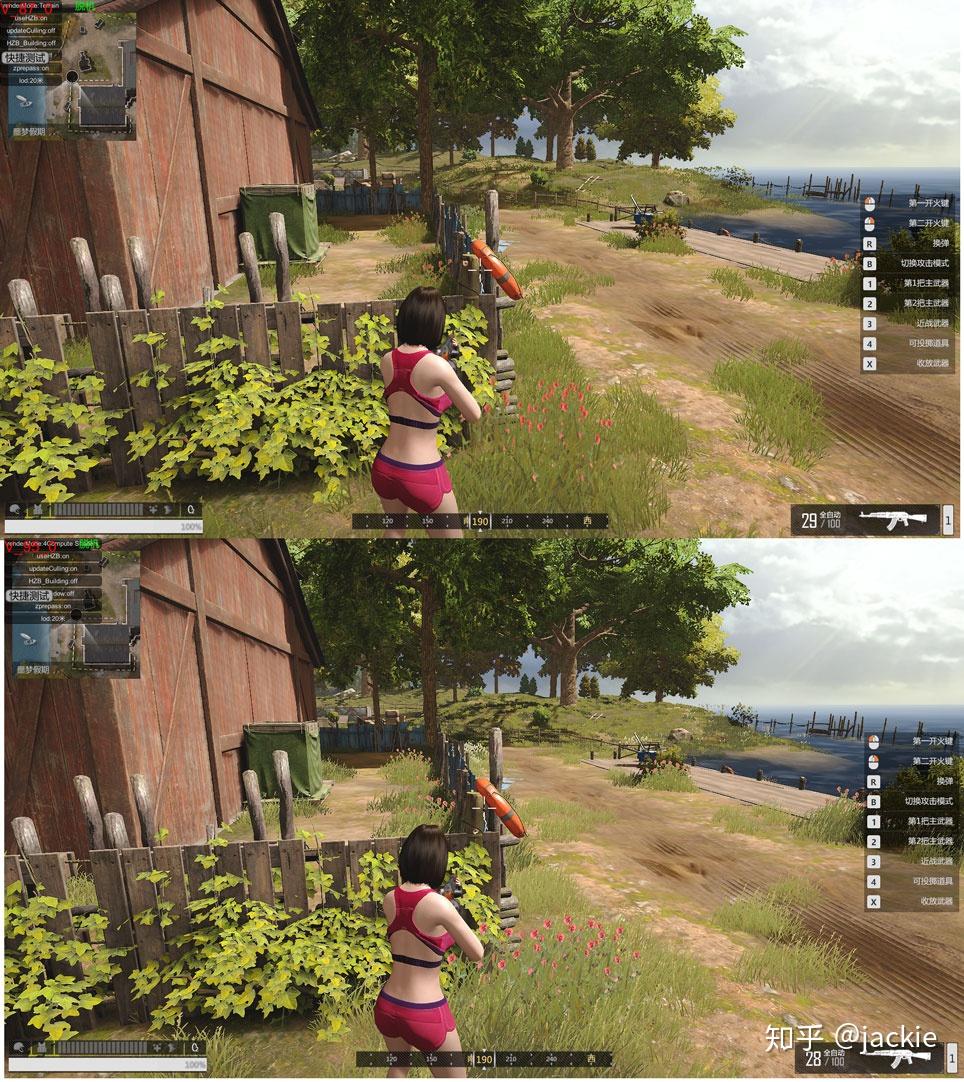 【Unity】使用Compute Shader实现Hi-z遮挡剔除(Occlusion Culling) 纹理映射(Texture mapping)