SRP底层渲染流程及原理 agile Posted on Oct 2 2021 优秀博文 > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [zhuanlan.zhihu.com](https://zhuanlan.zhihu.com/p/378781638) 前言 -- 近期的 Unity 官方分享会为我们介绍了 SRP 底层渲染流程及原理,本文进行一个简单的记录,也顺便加深自己的理解。 视频链接(空降 25:00): [Unity X 鬼泣 - 巅峰之战「Unity 大咖作客」线上分享会 — 动作手游鬼泣专场【回放】(QA 精彩,不要错过哦)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1M54y1572J?t=2673) 官方简要总结: [大咖作客 | 动作手游《鬼泣 - 巅峰之战》直播现场爆料,竟扯出这么多内幕!](https://mp.weixin.qq.com/s/RFx7v-lY_yE3Lv0whkWwIQ) SRP 简介 ------ 本文会提到 SRP 中一些关键类的底层实现原理,这些类的简单的介绍可参考: [王江荣:【Unity】SRP 简单入门](https://zhuanlan.zhihu.com/p/378828898) SRP 的简单架构 --------- 整个 SRP 的简单架构如下图: 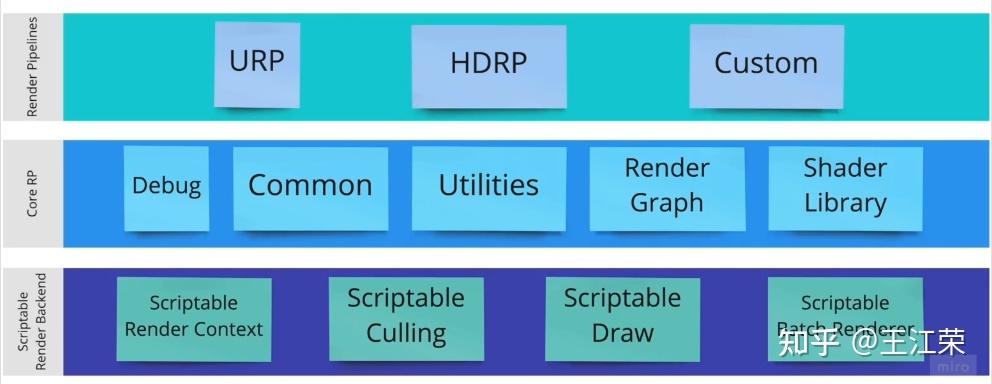 最上层为 **Render Pipelines**,有我们常见的 URP 跟 HDRP,还有自己去扩展的一些自定义的渲染管线。 中间层为 **Core Render Pipeline**,RP 层依赖于该层,为我们提供了一些 Common 库,Shader Library 等。 最下层为 **Scriptable Render Backend**,属于 c++ 层面,包括有 Context,Culling 和各种 Draw 函数,以及 SRP 特有的 SRP Batcher。 其中 Scriptable Render Backend 层对大部分开发者来说是一个黑盒,unity 本次分享的目的就是为了帮我们把这个黑盒打开,个人也在这记录一下,防止时间一久这个黑盒又对我关闭了。通过理解 Unity 在底层做了什么事情,我们更好的优化自己的项目(使用了 SRP,URP 或者 HDRP 的项目)。 Render Loop 流程 -------------- 我们先模拟视频里说到的 Demo,其实很简单,使用 URP 或者 HDRP 的环境即可,因为他们的都是在 SRP 的基础上扩展的。新建一个 Scene,里面随便放四个平行光源,都设置为实时光并且开启软阴影,如下图: 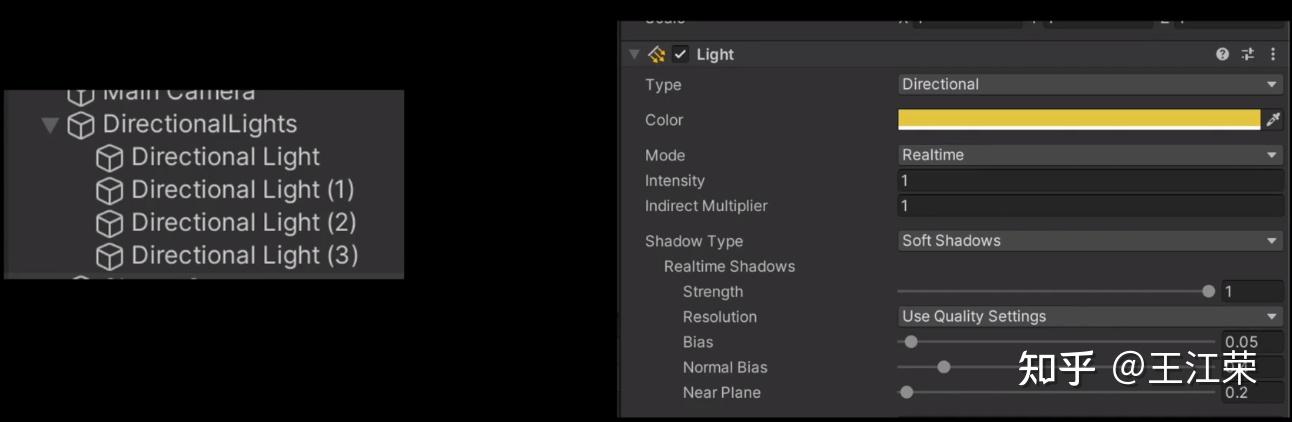 然后在场景中摆上茫茫多的 Cube,或者其他复杂的场景,然后它们的 Mesh Renderer 都要可以产生阴影,如下图:  这样我们的 Demo 就搭建成了(如下图),low 是 low 了点,但是不影响学习嘛。  我们运行一下,看看 Profiler 的 Timeline 视图: 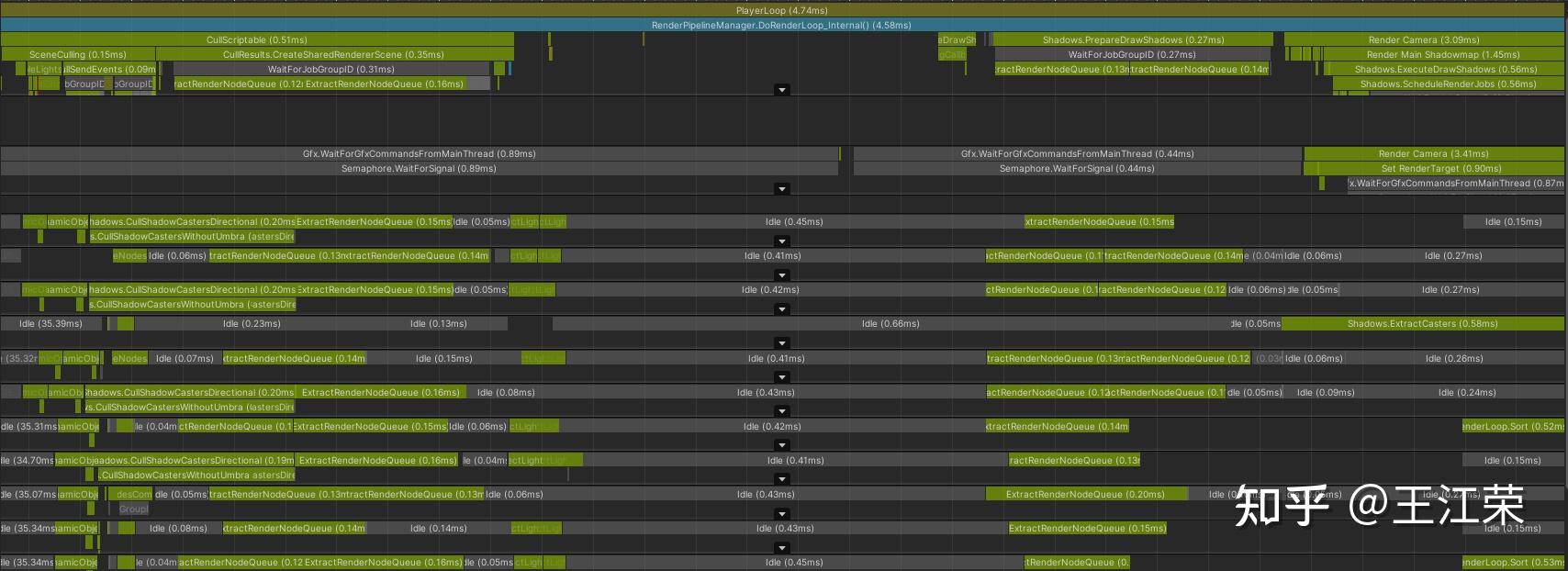 基本上可以看到整个 Render Loop 的过程,Render Loop 的官方解释为: > A render loop is the term for all of the rendering operations that take place in a single frame. Profiler 中各个节点代表着在一个 Render Loop 中各自负责的模块,其前后顺序自然就是每个模块的先后执行顺序。其中大部分模块都是通过 **Job System** 来实现的,也就是说我们的 SRP 本身是一个多线程的渲染。 本次分享主要提到了有 CullSceneDynamicObjects、Shadow.CullShadowCasterDirectional、ExtractRenderNodeQueue、RenderLoop.Sort、RenderLoopNewBatcher.Draw、SRPBatcher.Flush 这些节点。 Scriptable Culling ------------------ 我们先来看下 Profiler 中最前面的有关剔除的部分,其实就是我们在调用 **ScriptableRenderContext.Cull** 方法时,Unity 底层会做的一些事情。 ### Cull Dynamic Objects 首先最前面的是 CullSceneDynamicObjects,这部分其实是在**裁减场景里面的动态物体。**  这几个 job 会产生一个名为 **IndexList** 的数据结构。对于场景中所有的物体(Renderer),Unity 内部维护了 Renderer 的列表,而我们的 IndexList 就会存储当前**可见的**所有 Renderer 的数组下标。 我们通过一个例子来看一下这些 job 是怎么工作的,如下图: 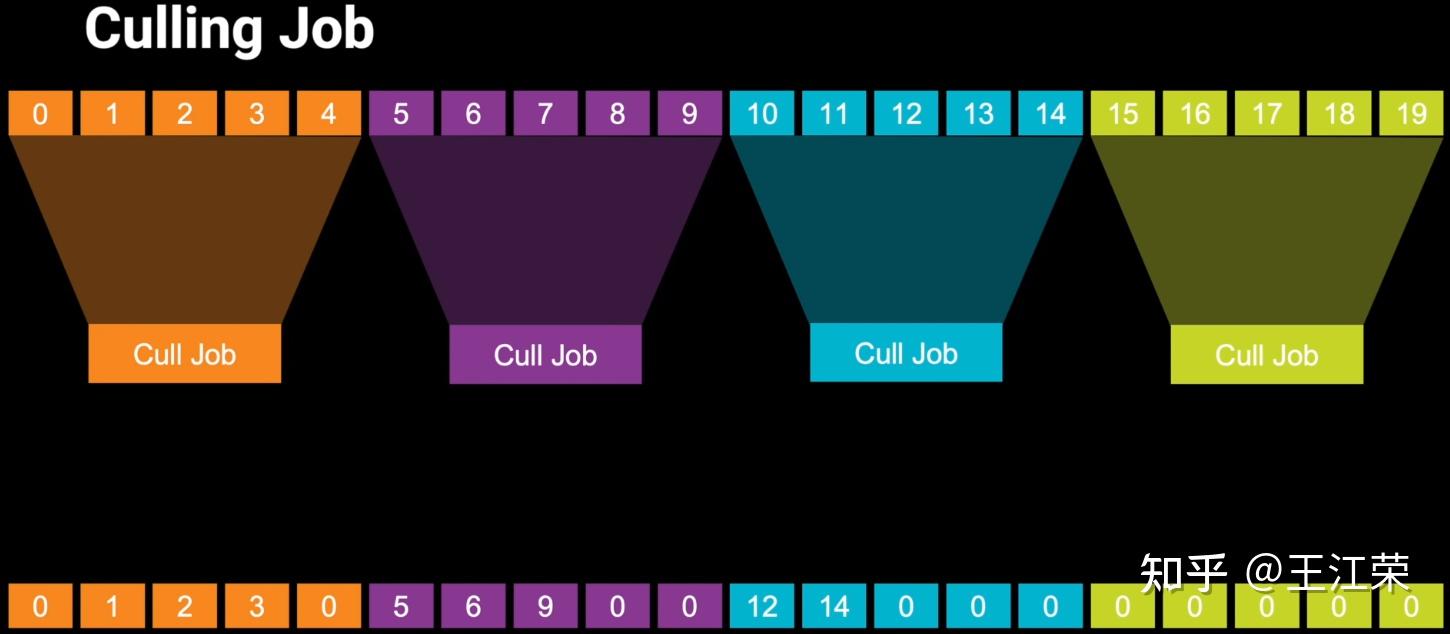 图中上面的部分从 0 到 19,这些其实就是 Unity 内部维护的 Renderer 的 list,也就是场景中所有的 Renderer。然后我们产生了 4 个 Job,分别处理 List 里面不同的部分。而底下的部分就是我们 IndexList,这里能看到一个特点,就是 **IndexList 跟 Renderer 的 list 是等长的**。 我们每一个 Job 处理裁减的时候,比如橘色这个 Job ,假设下标为 4 的 Renderder 是不可见的,那么 Cull Job 就会把 0、1、2、3 写到 IndexList 里面去。然后假设下标为 7 和 8 的 Renderder 是不可见的,那么紫色的 Job 会把 5、6、9 写到 IndexList 里面去。后面的 Job 操作类似,如下图: 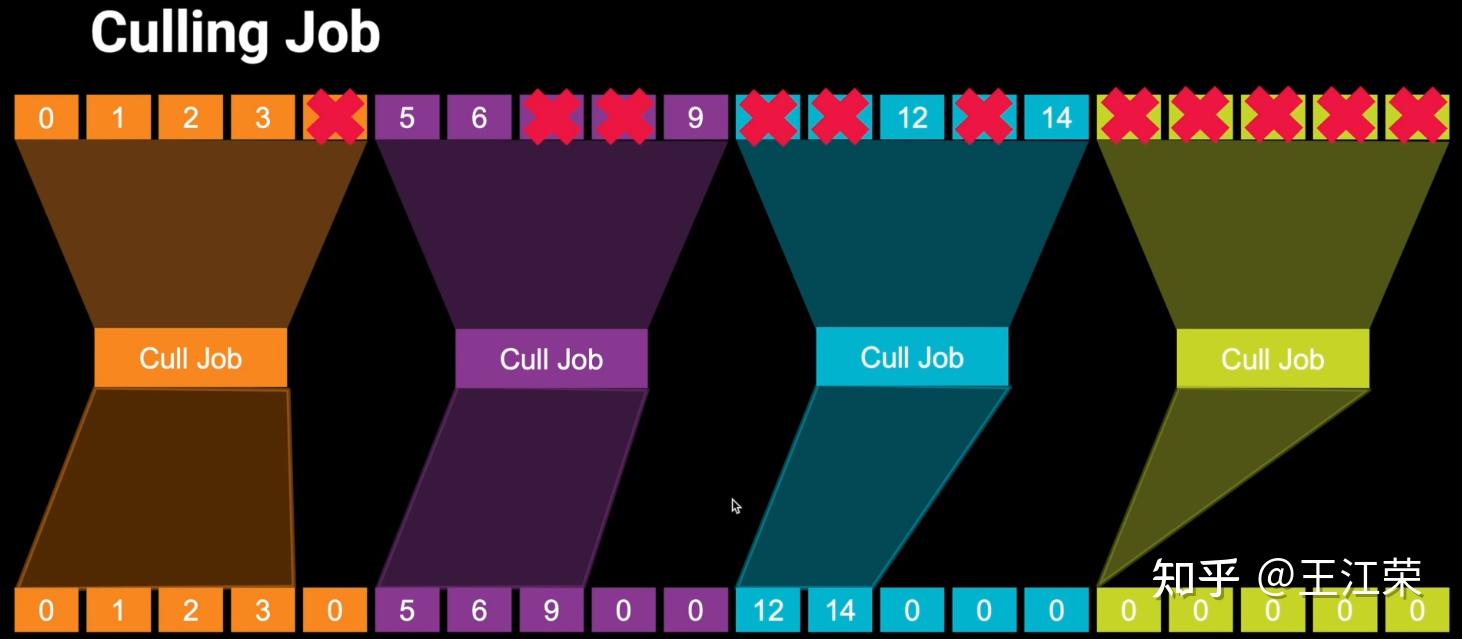 可以发现上面的操作中,并没有直接在 3 的后面插入我们的 5、6、9,而是写入在原本属于自己的那部分区间里,后续的 Job 也是如此。为什么要这么做呢? 这是因为 Unity 中每一个 Job 都是在不同的线程执行的,而上面每个 Job 处理 Renderer 的 list 时,互相之间没有任何的交集,即不会多个 Job 处理到相同下标的 Renderer,因此就**不需要引入锁的概念**,它们访问的所有的数据都是线程安全的。 当我们写入 IndexList 的时候也是同样的。当我们写入的时候,橘色 Job 只会往 01234 这五个里面写数据,紫色往 56789 这里面写数据,我们在写入的时候也是不用考虑锁的,每个 Job 读写的数据都是独立的,所以我们的 Job 里面是不需要给任何数据加锁的,这个就**保障了 Culling 过程的速度**。 当然这会带来一个小问题,就是我们产生的 IndexList 本身是不连续的,里面会有很多不可用的 0。因此 Unity 在 Culling Job 完成之后,会有一个 **Combine** 的操作,把不连续的 IndexList,就是把后面这些可用的数据拷到前面来,这样就会产生一个连续的 IndexList。示意图如下: 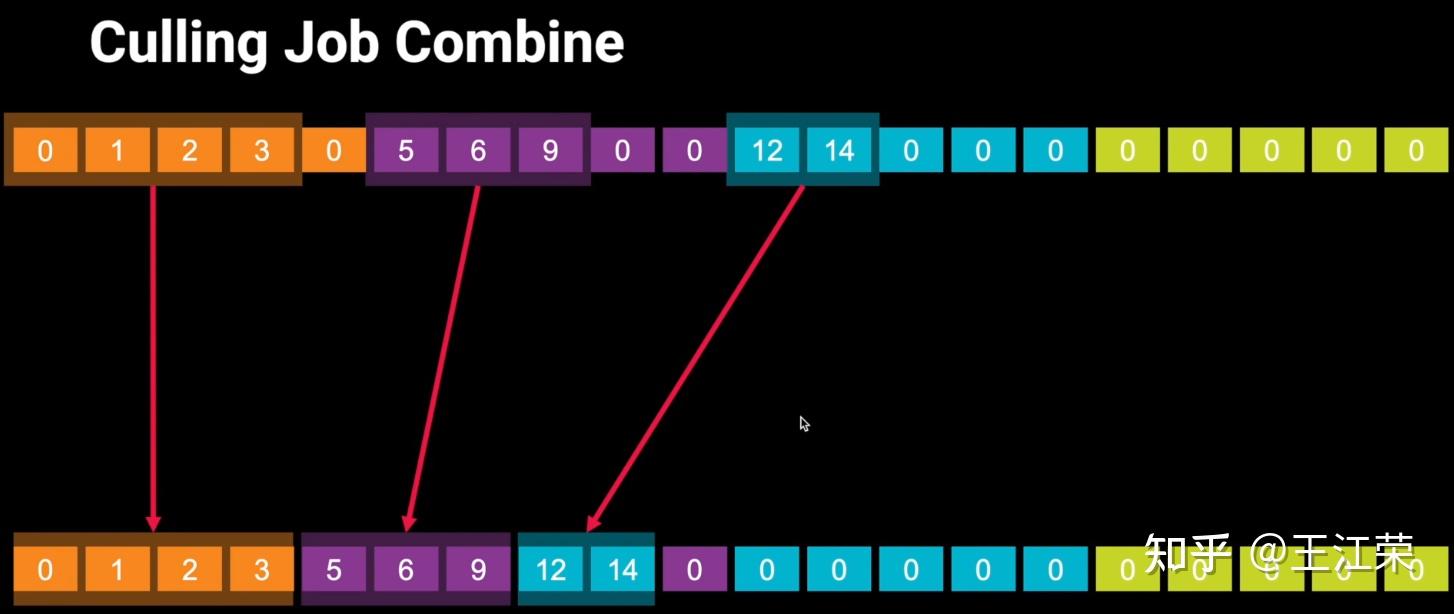 这时候我们就可以得到了场景里面目前可见的 Renderer 数组的下标,完成了场景里面动态物体裁减的过程。 ### Shadow Culling 可见物体有了,接下来就要进行有关阴影的剔除计算,其中就包括 Shadow.CullShadowCasterDirectional。因为我们的 Demo 中四盏灯,因此我们可以看下四块相关的 Job,如下图: 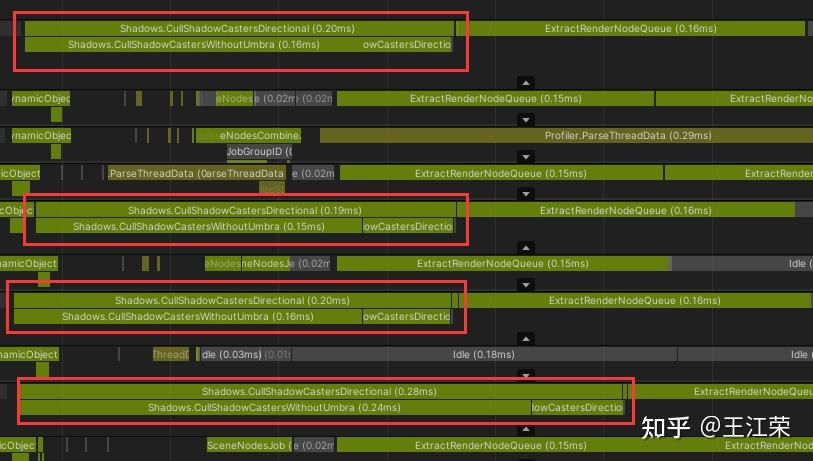 每块的高清无码图如下:  如果此时我们把场景中四盏灯光中其中三盏灯光的 Shadow 的选项改成 No Shadows:  再来看 Profiler ,可以发现相关 Job 变得只有一个了,如下图: 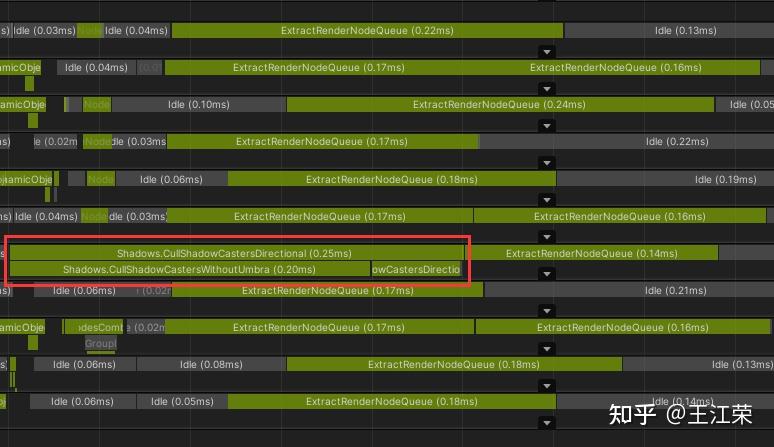 **因为 Unity 底层会为我们每一个产生阴影的灯光创建一个 Shadow 的 Job,去裁减我们整个的 Shadow。** 我们再来看看其中叫做 **Shadow.CullShadowCastersDirectionalDetnail** 的这部分,它跟什么有关系呢?我们继续修改我们场景里面的设置,我们把场景里面所有的 Renender 中产生阴影的选项给关掉。  这个时候再看下 Profiler ,可以发现这部分运行的开销也小了(所占的比例比上面的图小了很多)。  **因此如果想减少整个阴影部分的裁减开销,首先要去检查一下场景里的灯光是否有必要产生阴影,其次要去检查场景里的物体应不应该产生阴影,如果发现不合理的应该把这些选项都关掉,这样阴影裁减这部分的开销就能够降下来。** ### ExtractRenderNodeQueue 我们再来看看后面的 ExtractRenderNodeQueue 部分,如下图:  这一部分从耗时来看,比整个场景的动态物体裁剪的开销更大。  在理解它的作用之前,我们先来看下 Renderer 对象在内存里是怎么排布的,前面说到 Unity 里维护了一个 Renderer 的 List,但是所有的 Renderer 在我们的内存里其实是一个乱序的排布,示意图如下: 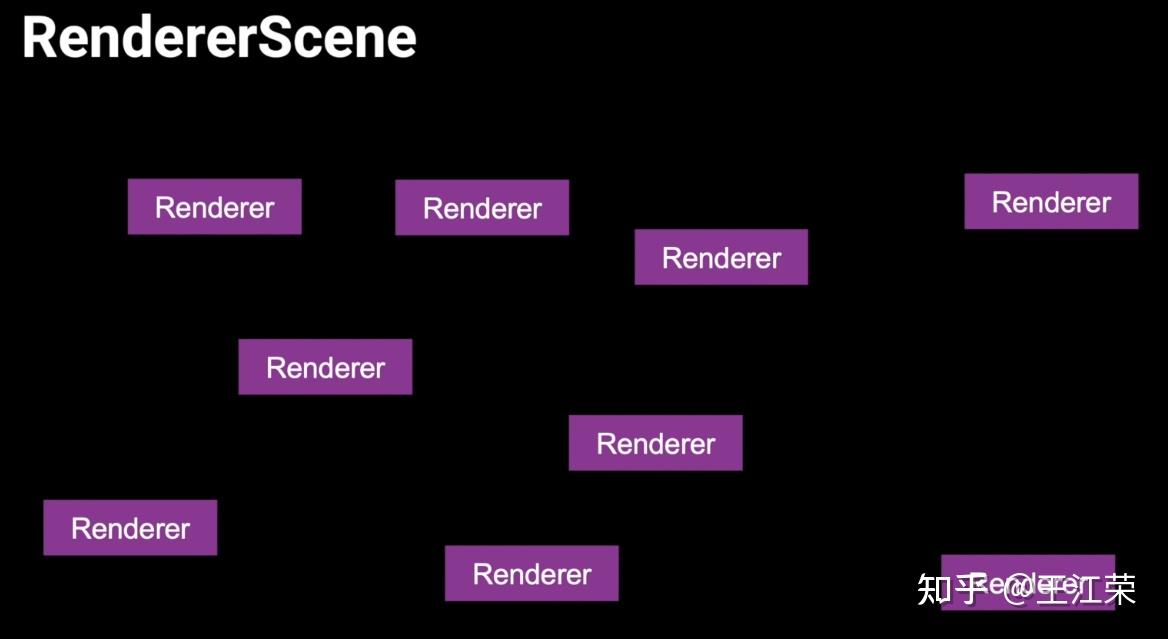 那么当我们尝试去**顺序读取** Renderer 对象的时候,造成的开销要比在内存里做连续的时候大得多。那么我们就要想办法把它们做成内存上连续的,来保证我们渲染的速度,Unity 因此引入了一个新的数据结构:**RenderNode**,它其实就是我们 Renderer 对象的一个扁平化的版本。**RenderNode 是一个非常大的全部都是值类型的 Struct**,Unity 会把 Renderer 里所有引用类型的数据展开然后拷贝到 RenderNode 里。RenderNode 本身在内存上是连续的数据,由 RenderNode 组成的队列我们称之为 **RenderNodeQueue**。RenderNodeQueue 本身是线程安全的,因此它能够被直接拿来做多线程渲染。 所以我们 ExtractRenderNodeQueue 的整个过程就是遍历所有目前可见的 Renderer 对象,然后把它里面的数据拷贝到 RenderNode 上,最后把 RenderNode 组成一个 RenderNodeQueue。示意图如下: 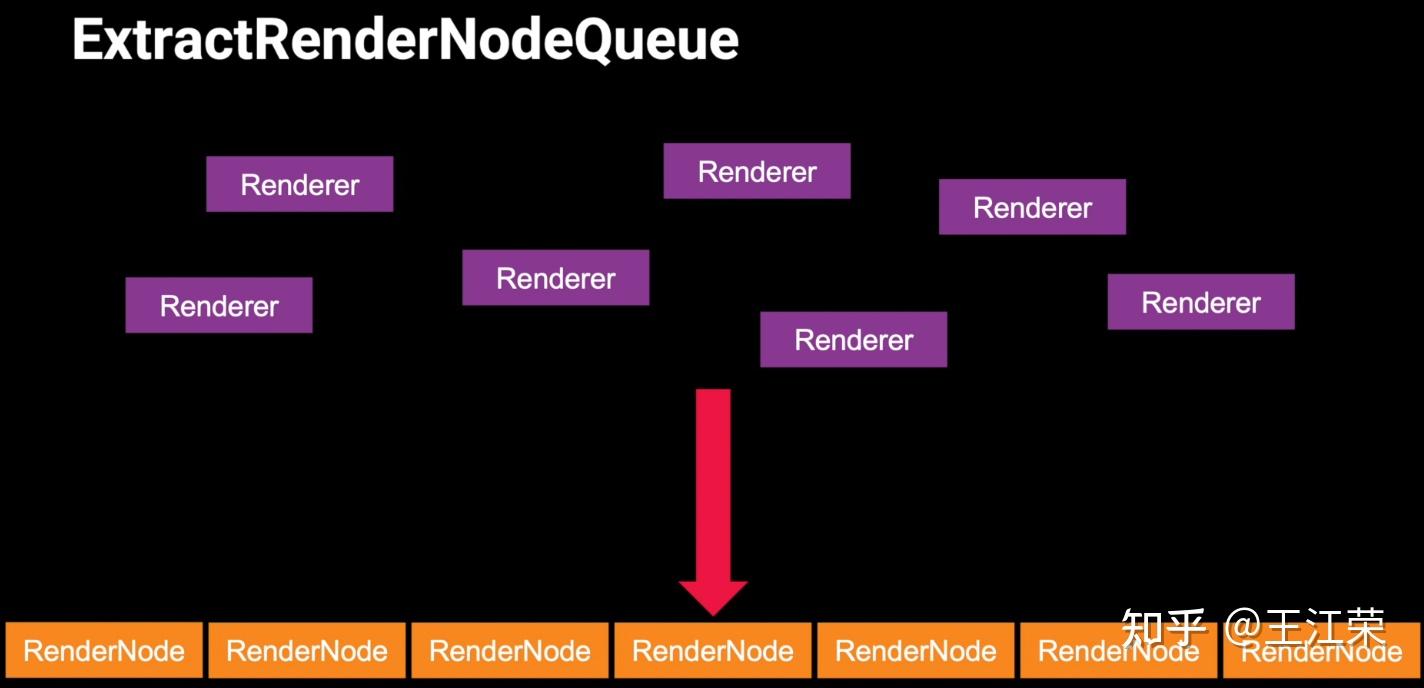 **如果我们想要降低这部分的开销,应该减少场景里面可见的 Renderer 数量**。 Scriptable Draw --------------- Culling 完成之后就是我们的 Draw 模块了,它不仅包含有 **CommandBuffer** 中常用的 **Blit**,**DrawMesh** 这些方法还包括 **ScriptableRenderContext** 里的 **DrawRenderers**,**DrawShadows** 这些。那么在这些 API 被调用的时候会发生什么样的事情呢?我们用 ExecuteCommandBuffer 和 DrawRenderers 来举例(其他都是一模一样的)。 我们先来看下引擎内部的这些 Commands 存储,如下图:  图中有 4 个 list,分别是 m_DrawShadowCommands,m_DrawRenderersCommands,m_CommandBuffers 和 m_Commands,我们来简单看看他们之间的关系。 假设 m_Commands,m_DrawRenderersCommands 和 m_CommandBuffers 三个 list 的初始样式如下:  当我们调用 DrawRenderers 的时候,会产生一个 DrawRenderersCommand,然后把这个 Command 加到 m_DrawRenderersCommands 中,如下图:  但是同时 Unity 也会产生一个 Command 对象,放到 m_Commands 中,如下图:  这个 Command 对象会记录 Command 的类型,例如示意图中橘色代表着 DrawRenderersCommand,紫色代表着 CommandBuffer,当然也会包括 DrawShadowCommands,示意图中省略了。而 Command 里记录的下标(刚刚新增的橘色 1)则是对应的 DrawRenderersCommand 在自己的 list 里的下标。 同理,那么假如我们在新增两个 CommandBuffer,那么除了在 m_CommandBuffers 里新增两个对象外,还会在 m_Commands 中新增两个对象,存储对应 Command 的类型以及下标,如下图:  **不管是调用 DrawShadows,DrawRenderers 还是 ExecuteCommandBuffer 的时候,其实就是在生成这个队列。也就是说我们在调用这些方法的时候,并不会立刻去进行相应的绘制操作,Unity 只是把它们存到相应的队列里去,这时没有做任何的渲染动作的。** 而什么时候去做渲染呢?就是我们下面要提到的 Submit。 Scriptable Render Loop ---------------------- 也就是 ScriptableRenderContext.Submit 方法底下做了什么样的事情。 整个 Render Loop 的伪代码如下: 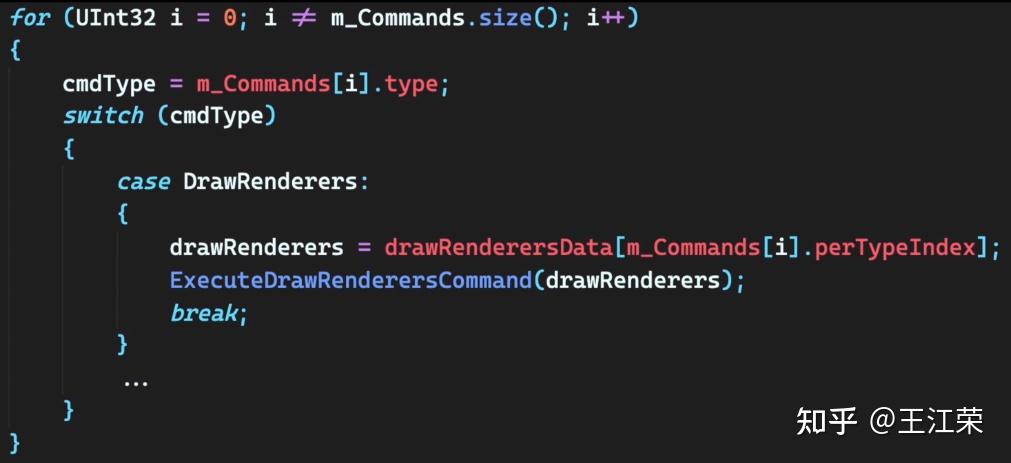 非常简单,就是一个 For 循环,遍历 m_Commands 队列。然后根据每一项的类型和下标,从 m_DrawShadowCommands,m_DrawRenderersCommands,m_CommandBuffers 中取得相应的对象,最后执行 **ExecuteDrawRenderersCommand** 来实现绘制。 ### PrepareDrawRenderersCommand PrepareDrawRenderersCommand 操作 Unity 并没有直接在 Profiler 里展示出来,它其实对应的是下面这个部分(Sort 之前):  在前面,我们通过 Culling 得到了 RenderNode 和 RenderNodeQueue,那么这些数据拿去做渲染是否已经足够了呢?我们知道一个 Renderer 会包含一个或多个的 Material,然后一个 Material 又会包含一个或多个的 Pass,然后我们还需要通过 Sort 来决定哪些东西先画哪些东西后画。 而 PrepareDrawRenderersCommand 的操作就是遍历我们所有的 RenderNode,然后找到里面所有的 Material,然后再遍历每个 Material 找到里面可以用的 Pass,根据每个 Pass 去生成一个 **ScriptableLoopObjectData**(简称 ObjectData)。示意图如下: 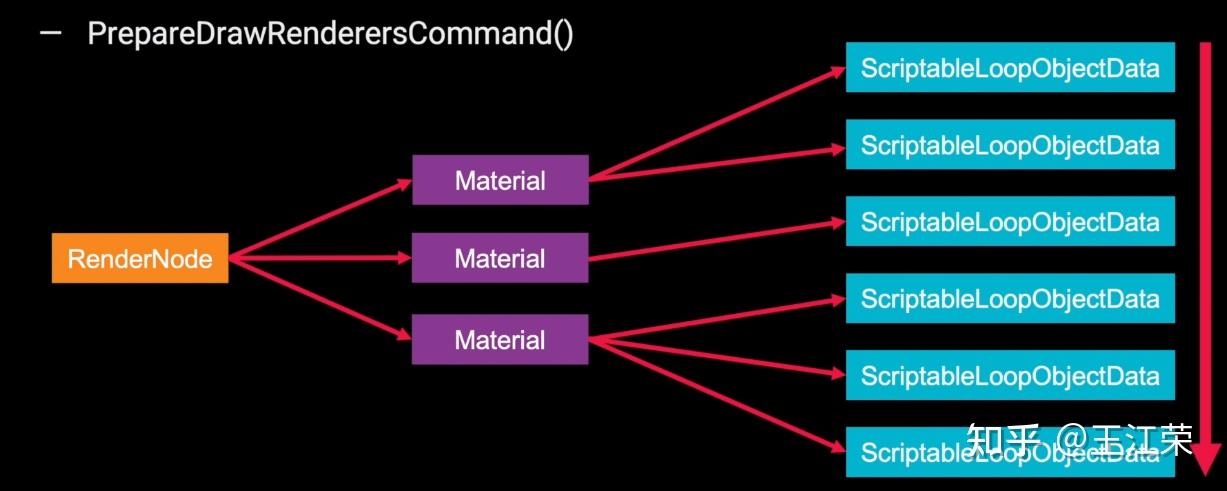 所有的 ObjectData 生成后,我们在对这些 ObjectData 进行一个排序,这样就可以得到一个确定的渲染顺序。然后我们做渲染的话就是拿到这些 ObjectData,然后逐一进行渲染就可以了。 ### ScriptableRenderLoopDrawDispatch 然后我们来看下 DrawRenderers 里具体的实现是怎么样的,如何进行 Dispatch,示意图如下:  **ObjectData 里会有个标识来记录是否兼容 SRP batcher**,例如图中橘色代表兼容,紫色代表不兼容。当我们排序完成后,ScriptableRenderLoopDrawDispatch 会根据 SRP batcher 是否兼容,找到所有的连续的 ObjectData,如下图:  前三个是兼容的,会全部丢到 SRP batcher 渲染器里做渲染。然后后面两个是不兼容的,就会被丢到传统的 Draw 渲染器里去。如下图:  这里就会发现一个问题,当我们判断 ObjectData 是否要进入 SRP batcher 的时候,我们只判断它们是否兼容 SRP batcher。也就是说如图中第一个 ObjectData 和第二个 ObjectData 它们可能本身是同一个 Shader,也有可能不是同一个 Shader,或者可能是同一个 Shader 不同的 Pass。也就是说它们有可能能被 batch 在一起,也有可能不能,这个问题后面 SRP batcher 部分再介绍。 SRP batcher ----------- 下图是官方文档提供的图:  很明显右边 SRP batcher 的复杂度更小,因此也更高效。SRP batcher 最核心的部分为:Bind with offset Object data from a large CBUFFER,它会为我们准备一个 large CBUFFER,**把 batch 里面每个 draw call 里小的 CBUFFER 组织成一个大的 CBUFFER,然后统一的去上传到 GPU**。工作流程如下图: 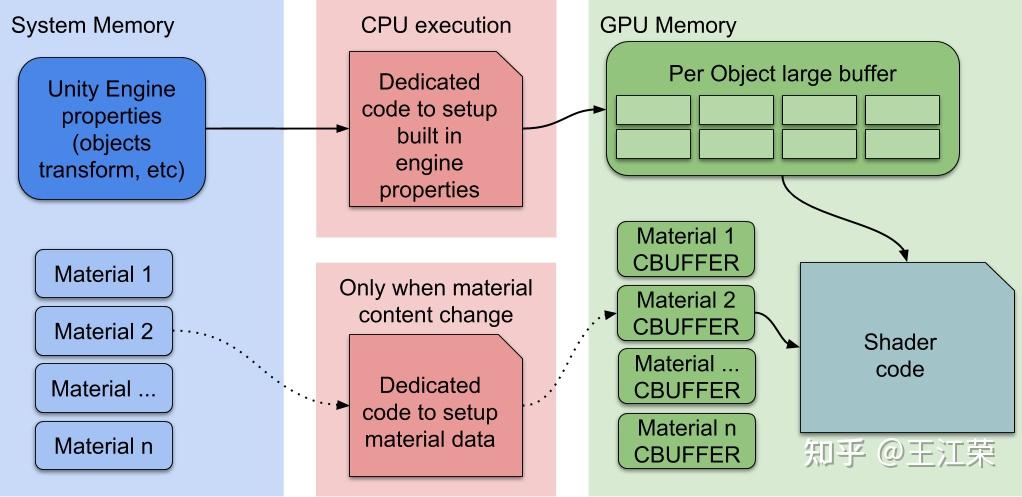 其中图中右上角 Per Object large buffer 部分,里面 8 个小方块就代表着 8 个小的 buffer,意味着一次的 batch 里面有 8 次的 draw call。每个 draw call 都需要一个小的 buffer,会把我们引擎内部一些内置的数据(比如 unity_ObjectToWorld)填充进去。然后我们为每个 Object 准备这些小 buffer,然后组成一个大 buffer,最后把这个大 buffer 一次性的传到 GPU 上。这些基本上就是我们 SRP batcher 做的工作,对应到 Profiler 里就是 RenderLoopNewBatcher.Draw 部分,如下图:  ### RenderLoopNewBatcher.Draw 然后我们来看看 RenderLoopNewBatcher.Draw 的工作原理,在前面 ScriptableRenderLoopDrawDispatch 后,我们知道哪些 ObjectData 会被传到 SRP batcher 中,如下图:  图中的代表着传到 SRP batcher 中的 ObjectData,我们会遍历这些 ObjectData,当解析第一个 ObjectData 时,会先创建一个 batch。然后再看第二个 ObjectData,看它能不能和前面的数据 batch 在一起,示意图颜色相同代表可以,因此前两个会被 batch 在一起。然后我们再看第三个 ObjectData,发现是紫色的了,说明不能和前两个进行 batch。这时就会产生一次 **Flush**,会把前面两个 ObjectData 变成一个批次拿去做渲染,同时创建一个新的 batch。然后再看后面的数据能否和当前的数据做 batch,如此循环到最后。这里就解释了前面 Dispatch 时提到的问题。 **也就是说 SRP batcher 它只是放宽了我们合批的条件,我们传统的那些优化方案,例如减少材质,减少 Shader 的数量,RenderQueue 的调整,通过 Sort 让能够合批的 Shader 尽量排在一起,他们依然是适用于 SRP batcher 的。** 下图为打断合批的原因:  这些枚举,我们可以在 Unity 的 Frame Debugger 中看到,并且能看见更详细的解释,根据错误可以进一步优化我们合批的情况。 举个例子,假如我们场景中有如下四个材质一样的 Cube:  然后我们查看 Frame Debugger,可以发现它们四个被 batch 在一起了。 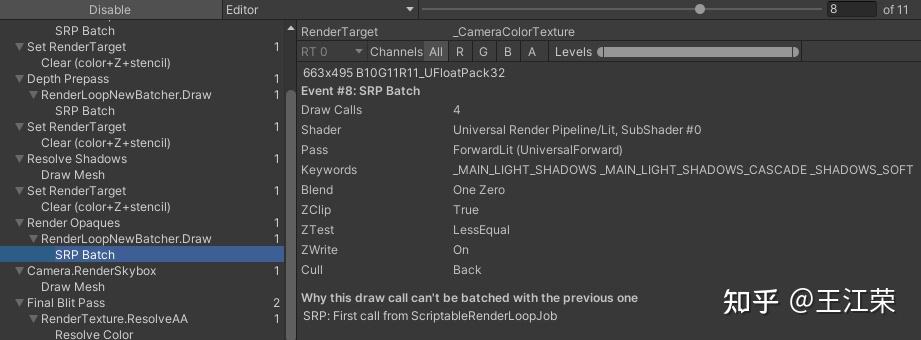 其中 First call from ScriptableRenderLoopJob 的介绍,就说明这个 batch 是第一个生成的。 接着我们新建一个 Material,使用 Unlit/Color 的 Shader,赋予其中一个 Cube,场景变为下面这样(最左边 Cube 用的自定义的 Material):  查看 Frame Debugger,会发现这个 Cube 没有被 Batch,因为我们使用的 Shader 不兼容 SRP Batcher。 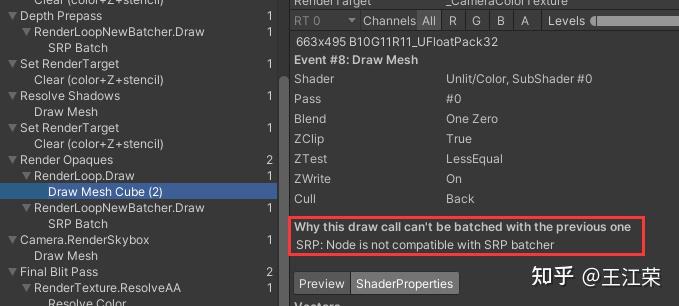 那么我们在换个兼容的 Shader,Material 里选择 Universal Render Pipeline/Unlit 的 Shader,再看下 Frame Debugger。 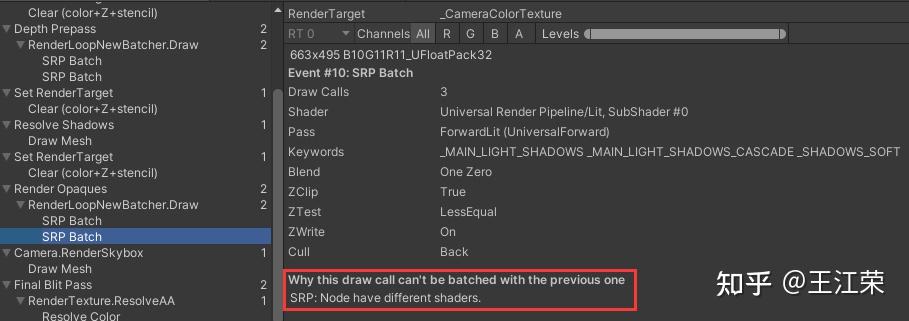 可以发现此时变成了两个 Batch,因为不同的 Shader。 ### SRPBatcher.Flush 前面提到的 Flush 操作,其实就是填充前面提到的 Per Object large buffer 里的小 buffer。  每个小 buffer 里的数据和其内存排布如下图: 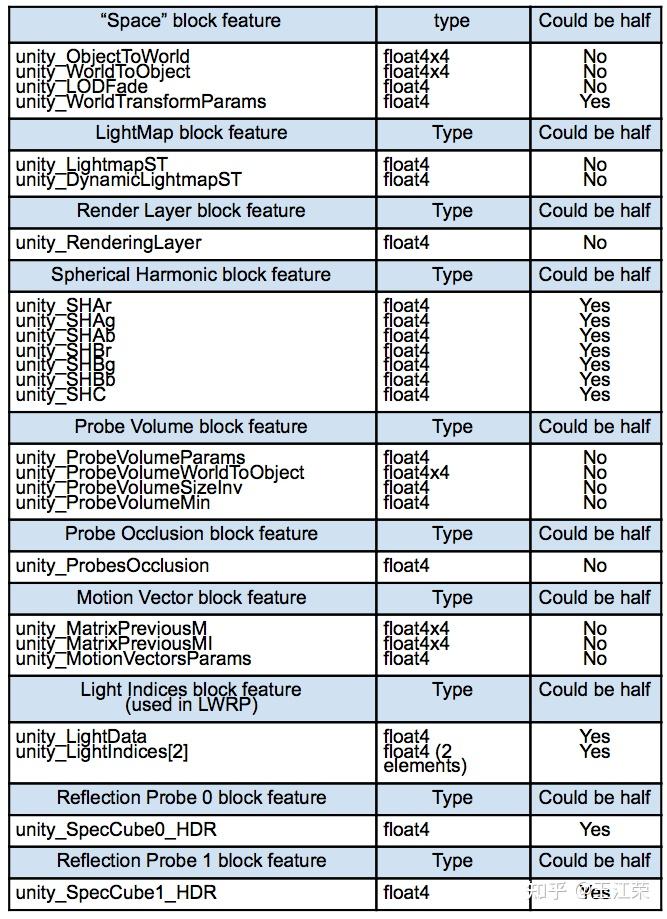 ### PerObjectBuffer 接下来我们来看下 PerObjectBuffer 是如何去填写这些数据的。当一个 Shader 确定的时候,这个 Shader 使用了哪些 **Feature** 就已经确定了,如下图:  比如说我们的 Shader 里使用了 BuiltInLightmapFeature,那么就会把 LightmapFeature 给它填充进去(数据参考上面的表格),如果没有使用就不会填这部分的数据。也就意味着我们的 **Shader 使用的 Feature 越少,我们一次能够合批的数量就会越多**。 填充完 PerObjectBuffer 后,就会把他们组成一个大的 CBUFFER(**PerObjectLargeBuffer**),然后统一的传到 GPU 做渲染,如下图:  Q&A 部分 ------ 1. **SRP batcher 是工作在 CPU 层面的,它做的事情就是减少 SetPass Call**。Unity 在很久以前就把 Draw Call 和 SetPass Call 做了区分:Draw Call 本身就是调用一个图形的 API,它本身的开销并不耗。而开销高是高在我们做切换渲染状态的时候要提前为显卡准备非常多的数据,也就是 SetPass Call 的工作,准备这些数据往往来说是开销比较高的。评判标准:不管是默认管线还是 SRP,SetPass Call 最好都不要超过 150,Draw Call 的话可以高一些。 2. **Vaulkan**:SRP batcher 在 CPU 层面的开销,比较可以关注的一个点是 android 上的 vaulkan,它已经越来越成熟,有不少项目在立项阶段把 vaulkan 作为首选的 API。其实使用了 vaulkan 的话,会有一个明显的发现就是,**vaulkan 在 CPU 上的开销要远远小于 OpenGL**。所以推荐!!! 3. **SRP batcher 和 GPU Instance 用的技术是差不多**,如果大家是想绘制单一的物体(像草这样的),推荐大家使用 GPU Instance。但是如果想做正常的场景渲染,比如说场景里的 material 多于 5 个,SRP batcher 的速度要比我们手动做 GPU Instance 要划算的多的。 参考: [https://blog.unity.com/technology/srp-batcher-speed-up-your-rendering](https://blog.unity.com/technology/srp-batcher-speed-up-your-rendering) Unity中使用ComputeShader做视锥剔除(View Frustum Culling) Unity内存分配和回收的底层原理