Unity内存分配和回收的底层原理 agile Posted on Oct 2 2021 优秀博文 > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [zhuanlan.zhihu.com](https://zhuanlan.zhihu.com/p/381859536) 前言 -- 又到了**高川**老师的干货分享时间,视频连接如下: [「Unity 技术开放日」北京站视频演讲_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1r44y1z7X3?p=2) 作为小迷弟依旧做一个文字版的笔记,这次分享的内容是对 **Unity 内存管理**这一块的深入介绍,也就是帮我们开黑盒。其实早期高川老师就已经分享过一次这方面的内容了,笔记如下: [王江荣:Unity 的内存管理与性能优化](https://zhuanlan.zhihu.com/p/362941227) 一开始以为这次的内容会和之前的差不多,实际上被打脸了,本次的分享会更加的深入讲解内存的分配与回收机制。此外老师还画了个大饼,提到了下面很多系统的底层,希望后续能够兑现这个饼,帮我们一一揭开这些黑盒。  其中 SRP 的黑盒已经由**李中元**老师帮我们揭晓了,可参考: [王江荣:【Unity】SRP 底层渲染流程及原理](https://zhuanlan.zhihu.com/p/378781638) 由于自己也是个萌新,特别是对于很多底层的东西,本篇笔记里加入了一些自己的理解,如果不对,望大佬们指正。 下面进入正题。 **Unity 由两部分内存来组成,原生内存(Native Memory)和托管内存(Managed Memory)**。其中 Native Memory 大家接触的会比较少,而且可操控性也比较少,例如 AssetBundle,Texture,Audio 这些所占的内存,这一部分内存是由 Unity 自身来进行管理的。我们平时开发通常会接触到的是 Managed Memory,也就是我们自己定义的各种类,如果这部分内存爆了,就需要我们自己去进行优化。 Native Memory ------------- 我们先来介绍一下 Native Memory,看看 Unity 是如何分配和释放内存的。 ### new/malloc 由于 Unity 是一个 C++ 引擎,那么分配和释放内存无非有下面两种方法: > 第一种 new 和 delete: > Obj *a = new Obj; > delete a; > 第二种 malloc 和 free: > Obj *a = (obj *)malloc(sizeof(obj)); > free(a); 那么它们的区别是什么呢?主要有如下几种: 首先 new 属于 c++ 的操作符(类似于 +、- 等),而 malloc 是 c 里面的函数,理论上来讲操作符永远快于函数。 其次 new 分配成功时,返回的是对象类型的指针,无须进行类型转换,而分配失败则会抛出 Exception。而 malloc 分配成功则是返回 void * ,需要通过强制类型转换变为我们需要的类型,分配失败只会返回一个空(NULL)。 然后还有非常重要的一点就是,malloc 基本上大家的实现是类似的,new 却各有各的不同。我们知道 new 会去调用构造函数(constructor),所以很多人会把 new 理解成 malloc+constructor,但是这种理解是错误的。**因为在 c++ 实现的 standard 里,你会发现 new 会不会调用 malloc 完全由 new 库的实现来自行决定**,也就是说 new 和 malloc 是两者独立的。 另外从严格的 c++ 和 c 的意义上来讲,他们分配内存的位置是不一样的,**new 会分配在自由存储区 (Free Store),而 malloc 会分配在堆(heap)上**。这两者的区别简单来说,你 new 分配的内存再 delete 后是否直接释放还给系统是由 new 自己来决定的,而 malloc 分配的内存再 free 后是一定会还回去的。 所以严格来讲 new 和 malloc 根本不是一件事,两者之间没有什么关系。 理解了原生的 new 和 malloc 之后就会发现,它们交给上层开发者去进行可控的单元其实并不多。也就是说当我去 new 的时候,具体 c++ 怎么去 new,实际上完全依赖于库实现。如果这个库实现的比较好,例如有些库的实现会包含内存池这样的机制,那么我们的 new 就不容易导致一些例如内存碎片化的问题。但是如果实现的并不好,就可能造成性能的瓶颈。 因此大部分的工业软件,在写软件的第一件事情就是去重载整个的 new 和 malloc,例如重载 operator new() 和 operator delete() 来重新定义 new 和 delete 操作符的功能。因此 Unity 也是这样的,即不会用原生的这套内存分配系统,而是自己去实现一套。 ### Unity 的内存管理 Unity 怎么做内存管理的呢?大致流程如下图: 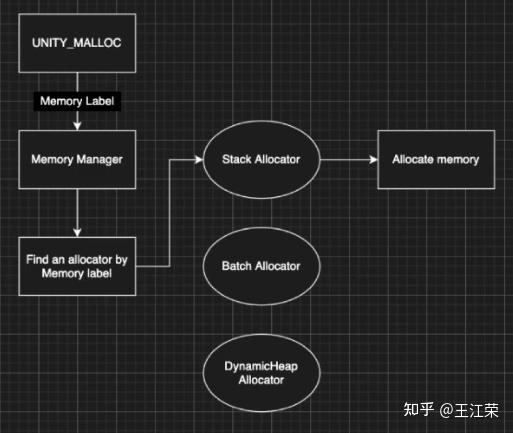 简单来说 Unity 会自定义一整套的宏,例如图中的 **UNITY_MALLOC**,此外也会有自己的 new 等一系列的宏。当 Unity 代码里面通过这个宏去分配内存的时候,实际上并不会直接去调用库函数(malloc)或者说是我们对应的操作符(new),而是会交到一个叫 **Memory Manager** 的管理器里。如果大家去看一下我们的 Profiler,里面会列出忙忙多的 Manager(如下图),但是却找不到 Memory Manager,因为我们看见的那些 Manager 信息大部分都是由它提供的,所以它自己并没有被包含进去。 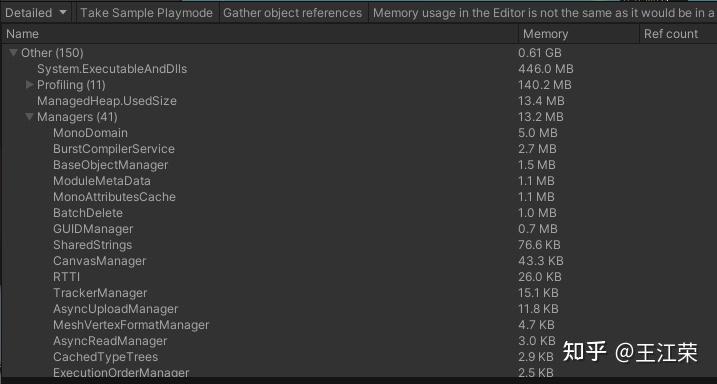 在日常的开发当中我们也会意识到 Unity 有很多的 Manager,比如说 MeshManager、SoundManager,但是很少会意识到 Unity 自己有一个 Manager,因为没把它写到 profiler 的数据里。 当 Unity 要去 malloc 一个东西的时候,我们会给这个内存一个标识符,也就是图中的 **Memory Label**。我们在 Profiler 的 Detailed 信息里,能够看见很多的分类,这些分类里面展示了各个项的内存占用情况,如下图: 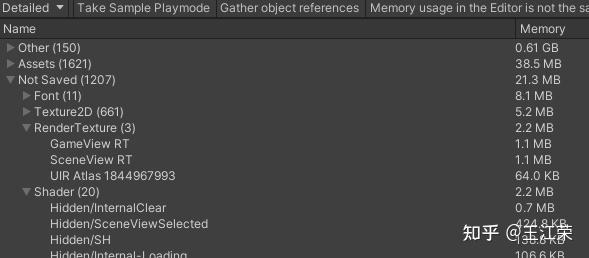 那么 Unity 如何在运行时区分出这块内存到底是谁的呢,就是通过 Memory Label 来进行区分的。 同时 Memory Label 还会帮 Memory Manager 去做一个筛选,Unity 在底层会有一系列的内存分配策略,不同的策略会对应不同的分配器。图中列举了三个简单的分配器:栈分配器(Stack Allocator),批量分配器(Batch Allocator,在 SRP 和 URP 系统里经常会用到,此处又是一个饼),和比较常用的动态堆分配器(DynamicHeap Allocator),在读 Unity 源码时会经常碰见他们。  因此 Memory Manager 就可以通过 Memory Label 知道我们要做什么样的内存分配,从而选择一个合适的分配器来帮我们分配出一块合适的内存。unity 底层大概有大概 15-20 种分配器,每种分配器适用的环境和它的场景是不同的。接下来我们举个例子,也就是栈分配器。 ### 栈分配器(Stack Allocator) 栈分配器它有三个特点: * 快 * 小 * 临时性 这个分配器大部分用来分配临时变量的。比如我们分配一个局部的内存,这个内存只在一个函数或者很短的一帧之内进行使用的话,可能就会用到它来进行分配。 它的内存结构如下:  图中一整个大块叫做一个 Heap Block,当我们要分配一块内存的时候,实际上 Unity 帮我们分配的两块的内存:Header 和 User。 Header 里面记录了我们当前这一次分配的一些信息,一般有如下几种: * 当前这块是不是要被删掉,即图中的 Deleted 标记。 * 下面 User 这块真正要给用户的区域要有多大,即一个 size。 * 当前这一块它前面的那一块是谁,应该是个指针吧。 User 就是我们用户分配使用区域。也就是假如我们去分配一个 16byte 大小的内存,实际上消耗的可能是 32byte 的大小,因为会有个头。 **这一整块内存在一开始的时候就已经预先分配好了,当我们进行栈分配的时候,实际上只是在不停的调整栈顶指针**。例如示意图中我们分配了三块内存,那么每次分配时栈顶指针的位置如下图:  可以看出它是依次向下分配,每次只在栈的顶端或者说这一块内存的尾部再去分配。当预先分配的这一整块 Block 被分配完之后,会再额外拓展一个新的来,拓展时需要去 malloc 一块新的内存,然后移动栈顶指针。当然这个拓展并不是无限拓展的,它有如下限制: * Editor 模式下,主线程里有 16MB 的大小,在任何一个子线程(worker)里面会有 256KB 的大小。 * Runtime 模式下,根据不同的平台,主线程里有 128KB-1MB 不等,每个子线程是 64KB。 接着我们来看看回收的情况,比如我们要回收尾巴那一块,怎么做呢?会先把 Header 里的 Deleted 标记为 1,表示这块内存无用了,然后把栈顶指针回弹,就做完了。如下图: 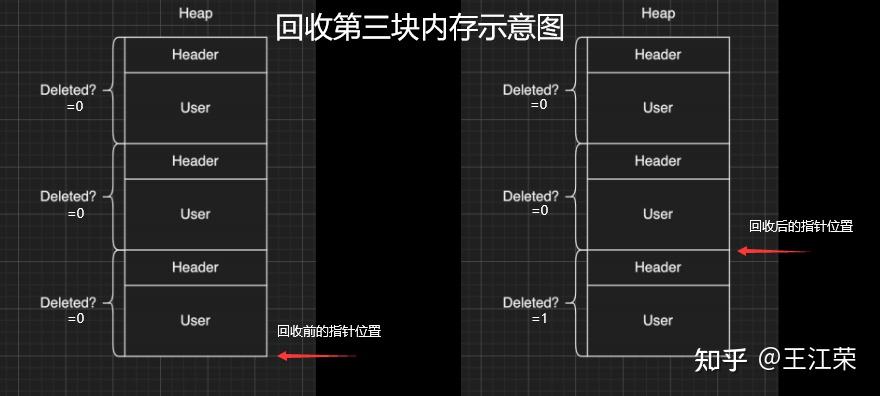 可以看出不管是分配还是回弹都是挪动栈指针,因此非常快。那么如果要回收中间那块的内存,要怎么做呢?那就更快了,只需要把中间的 Header 里的 Deleted 标记为 1,然后别的什么都不做。如下图:  这样就会有个疑问,中间这块内存将来怎么去用呢?其实在尾巴被回收的时候还会做一个额外的动作,就是当我把自己回收并且栈顶指针回弹的时候,会再去检查上一块是不是也被删除了(因此在 Header 里面存了上一块的信息),如果是栈顶指针就再次向上移动,直到找到一个没有被删除的块,或者挪到了整个 Block 的头。例如我先回收第二块,然后在回收第三块,那么此时栈顶指针会直接回弹到第一块的末尾。 那么如果有几十几百个块,但是我们尾巴那块打死都不放,那么中间那些内存就永远无法再被复用了。**因为我们只有回收最后一块的时候栈顶指针才会回弹,而每次分配都是从栈顶指针往下分配的**。因此这也是栈分配器的一个限制,它无法快速立刻去重用已经被释放的内存,只有等栈顶被释放的时候才能回去寻找这些连续内存。 理解了这个机制之后,再看三个特点就会非常好理解: * 快:因为每次分配只有移动指针,变更标记位,并没有做其他事情,**并不实际的去 malloc 一块内存出来**,所以非常非常的快。通过测试一万个对象的数据分配,它能比主分配器也就是动态堆分配器快三到五倍。 * 小:假如我分配了 512M 的内存给整个栈,会导致其中大量的内存可能会被浪费掉。因为这个 **Block 一旦申请出来就不会被释放了,不会还给系统**,所以这一块内存就永远在你的内存中杠着你,所以我们要设计的尽可能的小。 * 临时性:意味着内存栈会快速的收缩和膨胀,也就是说栈顶会经常的被释放,导致整个栈的内存可以高效和重复的利用。 上述这些原因也就是为什么我们的栈寄存器只用作临时的这块内存的分配。 ### MemoryManager.FallbackAllocation 有时候在我们通过 Profiler 底下那些 Tag 检查性能问题时,可能就会碰见一个叫 MemoryManager.FallbackAllocation 的 Tag,如下图:  如果你见过这个东西,那么恭喜你中奖!今天的课对你就非常的有用了,你就能知道自己为什么碰见它了。 这个东西是干什么的呢?简单来说,刚刚我们说栈大小只有 128KB-1MB,如果爆了怎么办。Unity 整体的设计原则不会让大家的程序 Crash。例如你拿到的 Shader 不一定是你想要的 Shader,但是绝对会保证你不出错;以及你写的 C# 可能会抛异常,但是绝对不会让你的游戏崩溃。这是 unity 设计的一个理念,会做一个**兜底行为(FallBack 机制)。**在写 Shader 时会要求你去写一个 FallBack,不写就 FallBack 到一个 Error Shader,也就是我们常见的紫红色效果,如下图:  对于整个栈管理同样有兜底机制,一旦用暴了,就会 **FallBack 到我们的主堆分配器**。主堆分配器的容量可以是非常非常大的,但是速度会比这个慢很多。因此当出现 FallBack 的时候,Unity 会帮很贴心的帮你输出 MemoryManager.FallbackAllocation 的 Tag。如果出现这个,会看见一个特别长的时间线,因为原来我们的分配可能就零点几毫秒,但是一旦 FallBack 出去就可能变成几毫秒,可以明显的感觉到一段东西加长。 什么时候可能出现呢?比如说我们的 Animation/Animator 系统,当我们的数据量很大的时候,Unity 在计算整个 Animator 的时候,是用了大量的 Tempory Location 内存,也就是说用了大量的栈。在这个过程中,就有可能因为我们数据量过大而把整个栈撑爆。一旦撑爆了就会看见这个前面说的 Tag,然后游戏出现卡顿。 这是因为动态堆分配的分配机制,分配原则和分配策略比这个要复杂很多,同时因为不能做 Block 的批量预分配,所以导致一次的分配会慢很多(老板再上一个饼)。 解决方法: 1. 减少每一帧的数据量,例如原来一帧处理 100 个,变成一帧处理 10 个,分 10 帧去处理,这个速度会比一帧去处理快很多。 2. 买 unity 源码,直接改底层代码,把栈加大一点就行了。 Managed Memory -------------- 接下来来讲讲托管内存,我们先来看下面一张图:  该图表示的是 Unity 的 Mono Memory,蓝色的线表示预留的内存(Reserve),绿色的线表示已经使用了的内存(Use)。前半部分我们可以发现当使用的内存快达到和预留内存一样大小时,Unity 会再申请一部分内存给预留内存。后半部分绿线突然降低说明此处发生了一次 GC,使得很多使用内存被回收,但是预留内存并不会被回收,依旧保持现有的大小。 如果我们想要预留内存也被回收,那么首先我们的 Scripting Backend 要选 IL2CPP,不能是 Mono。然后当一个 Block 连续 6 次 GC 都没有被访问到,这块内存会被返回给系统,蓝线就会下来,条件非常苛刻。(之前的分享里讲到 VM 内存池时提到过)  上面的曲线是我们正常使用的一个曲线,接下里来看一个不正常的曲线,如下:  不正常在哪呢?我们可以发现当我们在预留内存还明显足够的情况下,分配了一小块使用内存,此时却导致了预留内存的增加。导致这个现象的其中一个问题就是**内存碎片化**,例如我们内存池里还有 40byte 的内存,但是却是由 10 个 4byte 的碎片内存组成的,此时我们想要分配一个 6byte 的内存(连续的内存),却没有地方可以放得下,因此只能增加预留内存。 **因此内存池最根本的一个目的就是要减少内存碎片化**。但是实际开发中还是会经常出现这样的问题,例如我们频繁的分配小内存,把整个内存打的特别散,这样就会出现内存碎片化的问题。 官方文档: [undefined](https://docs.unity.cn/2021.1/Documentation/Manual/BestPracticeUnderstandingPerformanceInUnity4-1.html) ### Boehm GC 简单来看下 BDWGC(全称:Boehm-Demers-Weiser conservative garbage collector),也就是常说的 Boehm 回收器。其实它除了回收之外还做了很多分配的工作,甚至还可以用来检查内存泄漏。 而 Unity 用的是改良过的 BDWGC,它属于保守式内存回收。目前主流的回收器有如下三种: * 保守式回收(Conservative GC),以 Boehm 为代表。 * 分代式回收(Generational GC),以 SGen(Simple Generational GC)为代表。 * 引用(计数)式内存回收(Reference Counting GC),例如 Java 就是使用的这种,但是它是结合了保守式的引用式内存回收。 那么为什么 Unity 不用分代式的呢?分代式的是否更好呢?答案是,虽然分代式确实有很多的优点,但是它们都要付出额外的代价。例如分代式的 GC,它要进行内存块的移动,一块内存在频繁分配区长时间不动的话,会被移动到长时分配区,造成额外消耗。另外每次回收的时候还要进行一个评估,判断当前内存是否是一个活跃内存,这些东西都不是免费的,而是要消耗额外的 CPU 性能。当然 sGen 也有它的优势,例如它是可移动的,可以进行合并的(可以减少内存碎片)等等。但是在计算力本身就很紧张的移动平台上,再花费 CPU 去计算内存的搬迁和移动实际上是不合算的,引用计数也有类似的问题,所以 unity 还是使用相对比较保守的 Boehm 回收。 Boehm 回收有两个特点,一是不分代和不合并的,所以可能会导致内存碎片。二是所有保守式内存回收都是非精准式内存回收。 何为非精准?常规理解是我分配出去的内存你可能收不回来。实际上还有另一层意思:你没分配的内存你可能也用不了。也就是说,一是我已经分配出去的内存在没有人在引用它的情况下,不一定能收得回来。二是我没有分配使用的内存,当你想去分配使用的时候也不一定用的了。 我们来从 Boehm 内存管理的简单模型入手(如下图),来理解为什么会导致前面的问题。 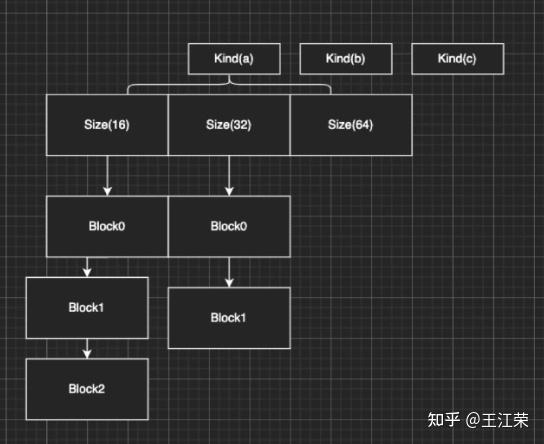 如图,Boehm 在内存管理的时候实际上是两级的管理。第一级我们叫做类型(Kind),实际上就是一个三个元素的数组 **GC_obj_kinds[3]**,如下图:  它们用来区分不同的类型,例如无指针类型(ptrfree)、一般类型(normal)和不可回收类型(uncollectable)。不可回收类型一般是回收器自己要用的一块内存,都会分配到 uncollectable。 每个 Kind 下面又包含一个列表:**ok_freelist[MAXOBJGRANULES+1]**,其中 MAXOBJGRANULES 值为 128,它也就是第二级的管理,如下图: 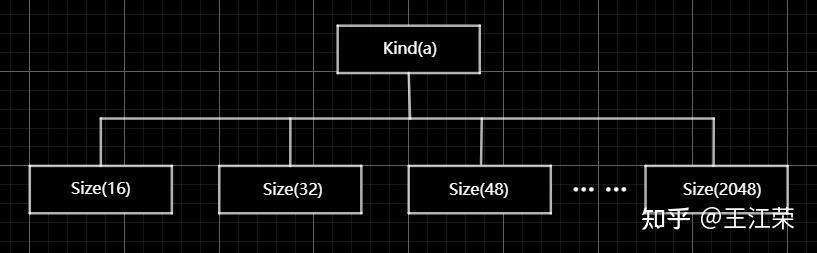 该数组中每一个元素它关联的内存块的大小,下标为 index 的元素对应大小为 16*index,因此下标为 0 的那个元素是没有用的。从下标为 1 元素开始对应着 16 字节,然后 32 字节,48 字节...,以 16 字节为增量,最多到 2KB(下标 128*16=2048)。 在每个 ok_freelist 元素下又挂着一层链表,如图:  链表里面的每个元素代表的就是一小块内存,其内存大小就是 ok_freelist[i] 对应的大小。例如图中 Size(16) 下面挂着 Block0,Block1,Block2,说明每个 Block 的大小都是 16 字节,Size(32) 下面每个 Block 自然都是 32 字节。 所以总体来说,我们有一个 GC_obj_kinds[3] 数组,然后每个 GC_obj_kinds 元素下面会有一个 ok_freelist[MAXOBJGRANULES+1] 数组。而 ok_freelist[index] 里存的是一个链表指针,指向大小为 index*16 的内存块。 假如现在我们分配一个小于等于 16 字节大小的内存,那么就会把 Size(16) 链表里的**空闲的**内存块拿出来给用户来用。比如我就分配 8 字节的内存,但是会拿到一个 16 字节的内存块,那么多出来的 8 字节内存就会被浪费掉。但是如果在 Size(16) 的链表里找不到可用的内存块,那么就会去找 Size(32) 的链表。如果在 32 字节里找到一个可用的内存块,由于我们要的内存只有 8 字节,明显小于 16,那么 Unity 会把这 32 字节的内存块一刀切成两块,给用户 16 字节,剩下的 16 字节挂到 Size(16) 的链表底下。若此时所有 Size(n) 里面都找不到可用的内存块,那么则会调用分配函数,分配较大一块内存,然后将大内存分割为小内存链表存储在 ok_freelist 中,可以理解为一个**内存池**。 假如我们先分配一个 16 字节的内存,使用掉 Size(16) 的 Block0,然后再分配一个 32 字节的内存,使用掉 Size(32) 的 Block0,此时这两块内存在物理上是连接的,虽然在逻辑上他们之前属于不同的链表。若此时这两块内存都不使用了,要回收它们,会怎么做呢?依旧分别插在对应的链表下么?并不是这样。当我们这两块内存同时被释放的时候,Unity 在释放第一个 Block0 的时候会去找后面的物理内存(也就是第二个 Block0)是否要被释放,发现这两块都要被释放的时候,那么就会把它们合并起来,让这个指针挂到更大的地方去,也就是 Size(48) 的链表下,从而去尽量减少整体内存碎片的问题。 也就是说 **Unity 尽量会把空闲出来的内存合并成一个较大的内存块**,同时以移动指针的方式(注意不是移动内存)把它挂到一个合适的链表下面,这就是整个内存分配的一个策略。 我们再来谈谈回收,以及为什么说他是非精准的原因。如下图,假如我们要回收 ObjectA。 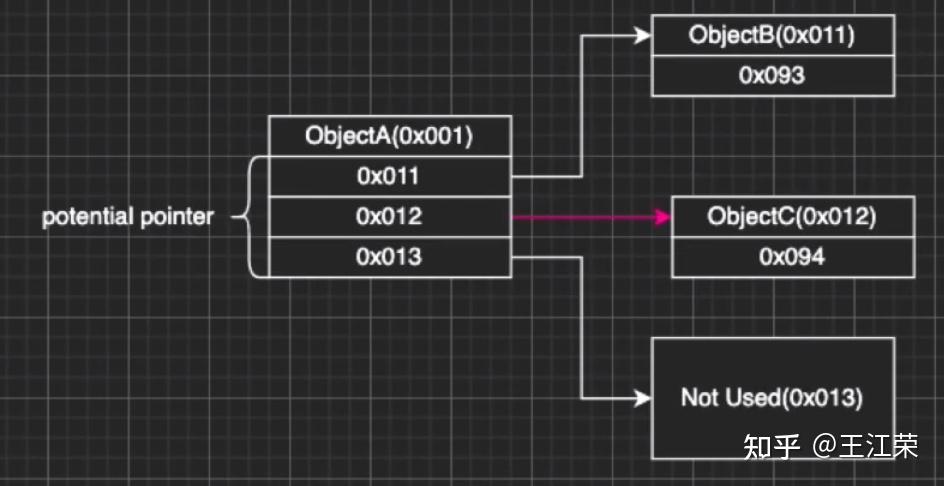 在保守内存回收器来看,当我要去回收一个内存块的时候,我会尝试找到这个内存块下面所有的指针(图中的 0x011-0x013)指向的地址,并且标记为引用。例如图中 ObjectA 引用 l ObjectB,当 ObjectA 发现不能被回收的时候,同时会标记 ObjectB 也不能被回收。这样的算法我们称之为**标记清除算法**(Mark&Sweep),即标记阶段通过标记所有根节点可达的对象,未被标记的对象则表示无引用、可回收,所有从堆中分配的内存 Boehm 中均有记录。 看着没什么问题,但是因为**在内存这个层次上已经没有了整个 class 的信息**,那怎么知道这个东西是一个数还是一个指针的呢?因为我们知道 c++ 一份内存里东西它可以表示任何东西,它可以是个数也可以是个指针地址,它是什么都可以,你转是什么。比如 0x011 它可能是个地址指向了 ObjectB,也可能单纯的就是个数而已。 那么我怎么知道它们是不是指针呢?Boehm 用猜的,所以我们管它们叫潜在指针(potential pointer),并不确定是不是一个真的指针。Boehm 会以一个 pattern 的方式来检查当前这个数有没有可能是一个指针。比如说我先去检查 0x011 地址里面有没有东西,发现有 ObjectB,那么 ObjectB 就不会被回收。然后检查 0x012,发现有 ObjectC,那么 ObjectC 同样就不会被回收。但是实际上我们的 0x012 并不是一个指针,也就是说逻辑上来讲 ObjectA 和 ObjectC 没有引用关系,但是恰好分配在 0x012 内存上。但是对于 Boehm 来说发现 0x012 指的这块地方有东西,因此 ObjectC 就回收不了。最后检查 0x013,发现它指向一块没有被使用的内存,那么 Boehm 就会把这块内存加到黑名单里,然后当你下次要进行大内存分配的时候,碰巧踩到了这个地址,Boehm 会告诉你这块内存你不能用,得再去分配一块。这样就很好理解前面所说的非精准了,你要回收的内存可能收不回来,对于你没用的内存他也可能不让你用。 所以我们在做内存分配的时候要考虑**先分配大内存,再分配小内存**。因为当我们先分配大内存的时候,内存中对象较少,产生内存碎片和产生黑名单的概率都比较低。因为只有在分配大内存的时候,分配器才会去参考黑名单,看看这块内存是不是被黑掉了。如果我们先分配小内存,那么我们内存中的 Object 就会非常多,那么产生黑名单的概率就会变大,然后再分配大内存的时候就有可能你分配 1MB 内存,它给了你 50MB 内存用掉了,因为剩下那些内存全部被黑名单了(连续黑名单)。 另外一个原因是,当你先去分配大内存,比如 1024 字节的内存,用过大内存把它释放掉之后,那么这块内存就会被放到 Size(1024) 下。然后当我们需要扩展内存池的时候,会优先把已经分配出来的大内存切成一个个的小块,再去重复利用,并不会再去像系统申请新的物理内存。也就是说当我们先分配大内存再分配小内存的时候,之前表里的 block 会变多。 先分配小内存的话,此时内存已经被切散了,大的 block 都被变成一个个小的 block 了,当我们这些小内存被回收的时候,如果被回收的部分在物理上不是连续的,那么永远不会变回一个大的 block。这样当我们需要扩展内存池的时候,就再也分配不出大内存,只能找系统去要了。就出现了之前曲线图里面的异常情况,再也分配不出来了,或者分配的这块被黑名单了,所以不得不再去向系统要一块内存。 GC 相关的部分参考自: [Testplus:解读 MONO 内存管理和回收](https://zhuanlan.zhihu.com/p/41023320) SRP底层渲染流程及原理 lua中的字符串操作(模式匹配)